To address this limitation, recent research has explored agent evolution techniques that aim to automatically enhance agent systems based on interaction data and environmental feedback. This emerging …
Abstract—Diffusion Language Models (DLMs) are rapidly emerging as a powerful and promising alternative to the dominant autoregressive (AR) paradigm. By generating tokens in parallel through an iterati…
1 Introduction Reinforcement learning (RL) has emerged as a new scaling paradigm for enhancing the capabilities of large language models (LLMs) by enabling thinking abilities [52]. Given a prompt, RL…
Abstract: Recent advances in prompting techniques and multi-agent systems for Large Language Models (LLMs) have produced increasingly complex approaches. However, we lack a framework for characterizin…
In this paper, we introduce a novel learning paradigm for adaptive Large Language Model (LLM) agents that eliminates the need for fine-tuning the underlying LLMs. Existing approaches are often either …
In this white paper, we present AlphaEvolve, an evolutionary coding agent that substantially enhances capabilities of state-of-the-art LLMs on highly challenging tasks such as tackling open scientific…
While AI systems demonstrate exponentially improving capabilities, the pace of AI research itself remains linearly bounded by human cognitive capacity, creating an increasingly severe development bott…
Why do thinking language models like DeepSeek R1 outperform their base counterparts? Despite consistent performance gains, it remains unclear to what extent thinking models learn entirely new reasonin…
Abstract—Intelligence is fundamentally non-ergodic: it emerges not from uniform sampling or optimization from scratch, but from the structured reuse of prior inference trajectories. We introduce Memor…
Language models traditionally utilized for cross-domain generalization in natural language understanding and generation have recently demonstrated task-specific reasoning through inference-time scalin…
We introduce the Byte Latent Transformer (BLT), a new byte-level LLM architecture that, for the first time, matches tokenization-based LLM performance at scale with significant improvements in inferen…
Recent efforts have incorporated large language models (LLMs) with external resources (e.g., the Internet) or internal control flows (e.g., prompt chaining) for tasks requiring grounding or reasoning.…
To address the challenge of policy learning in open-domain multi-turn conversation, we propose to represent prior information about dialog transitions as a graph and learn a graph grounded dialog poli…
Most of today’s AI systems are constrained by human-designed, fixed architectures and cannot autonomously and continuously improve themselves. The scientific method, on the other hand, provides a cumu…
Deep research agents, powered by Large Language Models (LLMs), are rapidly advancing; yet, their performance often plateaus when generating complex, long-form research reports using generic test-time …
In this paper, we propose a simple yet effective method to stabilize extremely deep Transformers. Specifically, we introduce a new normalization function (DEEPNORM) to modify the residual connection i…
We introduce DeepSeek-V3.2, a model that harmonizes high computational efficiency with superior reasoning and agent performance. The key technical breakthroughs of DeepSeek-V3.2 are as follows: (1) De…
Task-oriented conversational systems often use dialogue state tracking to represent the user’s intentions, which involves filling in values of pre-defined slots. Many approaches have been proposed, of…
Controlling the behavior of language models (LMs) without re-training is a major open problem in natural language generation. While recent works have demonstrated successes on controlling simple sente…
Deploying Large Language Models (LLMs) in streaming applications such as multi-round dialogue, where long interactions are expected, is urgently needed but poses two major challenges. Firstly, during …
Reinforcement Learning (RL) has proven highly effective at enhancing the complex reasoning abilities of Large Language Models (LLMs), yet underlying mechanisms driving this success remain largely opaq…
On the other hand, Transformers with self-attention still struggle to efficiently process long context equivalent to years of human experience, in part because they are designed for nearly lossless re…
Inference-time computation techniques, analogous to human System 2 Thinking, have recently become popular for improving model performances. However, most existing approaches suffer from several limita…
We explore an evolutionary search strategy for scaling inference time compute in Large Language Models. The proposed approach, Mind Evolution, uses a language model to generate, recombine and refine c…
Transformer language models have demonstrated impressive generalization capabilities in natural language domains, yet we lack a fine-grained understanding of how such generalization arises. In this pa…
Large Language Models (LLMs) have demonstrated remarkable progress in reasoning across diverse domains. However, effective reasoning in real-world tasks requires adapting the reasoning strategy to the…
Structured reasoning over natural language inputs remains a core challenge in artificial intelligence, as it requires bridging the gap between unstructured linguistic expressions and formal logical re…
However, the sequential decision making setting poses additional challenges having a lower tolerance for errors since the environment’s stochasticity or the agent’s actions can lead to unseen, and som…
How should future neural reasoning systems implement extended computation? Recursive Reasoning Models (RRMs) offer a promising alternative to autoregressive sequence extension by performing iterative …
We present Quasar-1, a novel architecture that introduces temperature-guided reasoning to large language models through the Token Temperature Mechanism (TTM) and Guided Sequence of Thought (GSoT). Our…
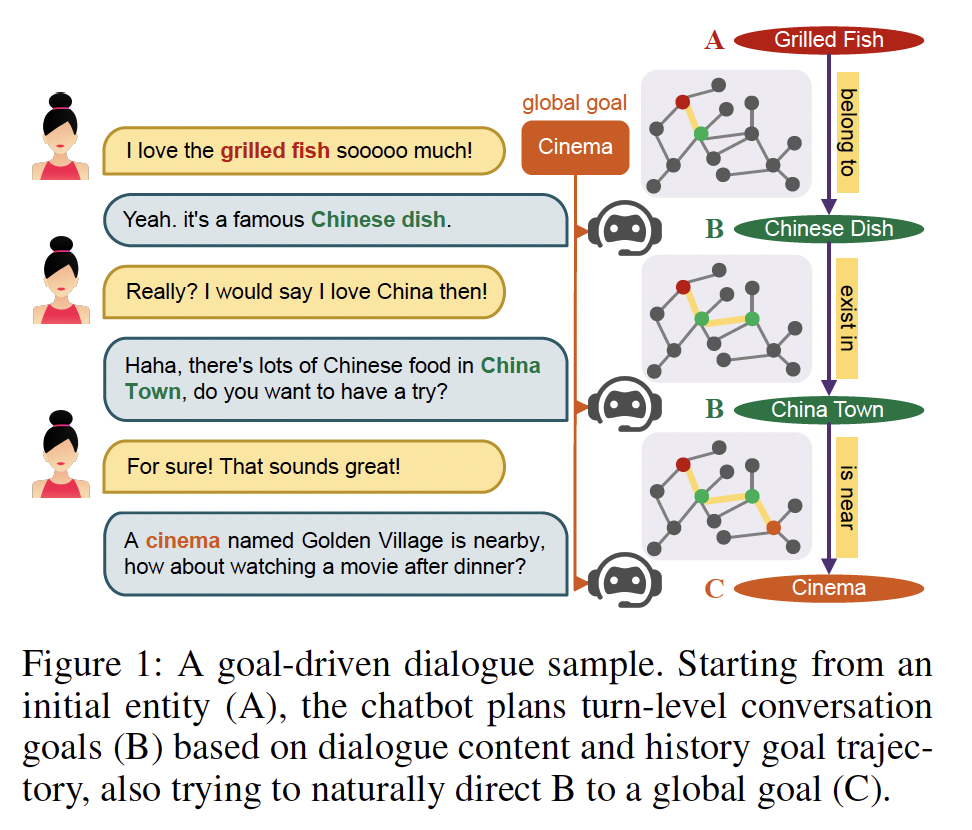 Human conversations are guided by short-term and longterm goals. We study how to plan short-term goal sequ…
Recently, large reasoning models have demonstrated strong mathematical and coding abilities, and deep search leverages their reasoning capabilities in challenging information retrieval tasks. Existing…
Reasoning, the process of devising and executing complex goal-oriented action sequences, remains a critical challenge in AI. Current large language models (LLMs) primarily employ Chain-of-Thought (CoT…
Self-improving AI systems aim to reduce reliance on human engineering by learning to improve their own learning and problem-solving processes. Existing approaches to recursive self-improvement typical…
“This paper delves into an advanced implementation of Chain-of-Thought-Prompting in Large Language Models, focusing on the use of tools (or "plug-ins") within the explicit reasoning paths generated by…
![[Pasted image 20251216072354.png]] Designing efficient and effective architectural backbones has been in the core of research efforts to enhance the capability of foundation models. Inspired by the…
We present Jamba, a new base large language model based on a novel hybrid Transformer-Mamba mixture-of-experts (MoE) architecture. Specifically, Jamba interleaves blocks of Transformer and Mamba layer…
Large language models (LLMs) have emerged as powerful tools capable of accomplishing a broad spectrum of tasks. Their abilities span numerous areas, and one area where they have made a significant imp…
Can we leverage LLMs to model the process of discovering novel language model (LM) architectures? Inspired by real research, we propose a multi-agent LLM approach that simulates the conventional stage…
Transformer-based large language models are increasingly used for long-horizon tasks; however, their attention mechanism scales poorly with context length. To handle this, we study a sleep-like consol…
We introduce a new paradigm for building large causal models (LCMs) that exploits the enormous potential latent in today’s large language models (LLMs). We describe our ongoing experiments with an imp…
Autoregressive models (ARMs) are widely regarded as the cornerstone of large language models (LLMs). We challenge this notion by introducing LLaDA, a diffusion model trained from scratch under the pre…
In recent years, large pre-trained language models (LLMs) have demonstrated the ability to follow instructions and perform novel tasks from a few examples. The possibility to parameterise an LLM throu…
Recently, increasing attention has been drawn to improve the ability of Large Language Models (LLMs) to perform complex reasoning. However, previous methods, such as Chain-of-Thought and Self- Consist…
Multi-agent systems (MAS) extend large language models (LLMs) from independent single-model reasoning to coordinative system-level intelligence. While existing LLM agents depend on text-based mediatio…
Abstract Linear attention is an efficient attention mechanism that has recently emerged as a promising alternative to conventional softmax attention. With its ability to process tokens in linear compu…
The structure of causal language model training assumes that each token can be accurately predicted from the previous context. This contrasts with humans’ natural writing and reasoning process, where …
Foundation models are applied in a broad spectrum of settings with different inference constraints, from massive multi-accelerator clusters to resource-constrained standalone mobile devices. However, …
Large Language Models (LLMs) employ autoregressive decoding that requires sequential computation, with each step reliant on the previous one’s output. This creates a bottleneck as each step necessitat…
“Large Language Models (LLMs) are currently capable of generating human-like responses in open-domain tasks [4]. This has led to a new generation of conversational agents, such as chatGPT, which are n…
Ultra-long-context capability is becoming indispensable for frontier LLMs: agentic workflows, repositoryscale code reasoning, and persistent memory all require the model to jointly attend over hundred…
We introduce MiniMax-M1, the world’s first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning …
Open-source Large Language Models (LLMs) increasingly specialize by domain (e.g., math, code, general reasoning), motivating systems that leverage complementary strengths across models. Prior multi-LL…
Soft attention is a critical mechanism powering LLMs to locate relevant parts within a given context. However, individual attention weights are determined by the similarity of only a single query and …
Long-context modeling is crucial for next-generation language models, yet the high computational cost of standard attention mechanisms poses significant computational challenges. Sparse attention offe…
In the previous sections, we discussed the concept of nested learning and how existing well-known components of neural networks such as popular optimizers and architectures fall under the NL paradigm.…
Over the last decades, developing more powerful neural architectures and simultaneously designing optimization algorithms to effectively train them have been the core of research efforts to enhance th…
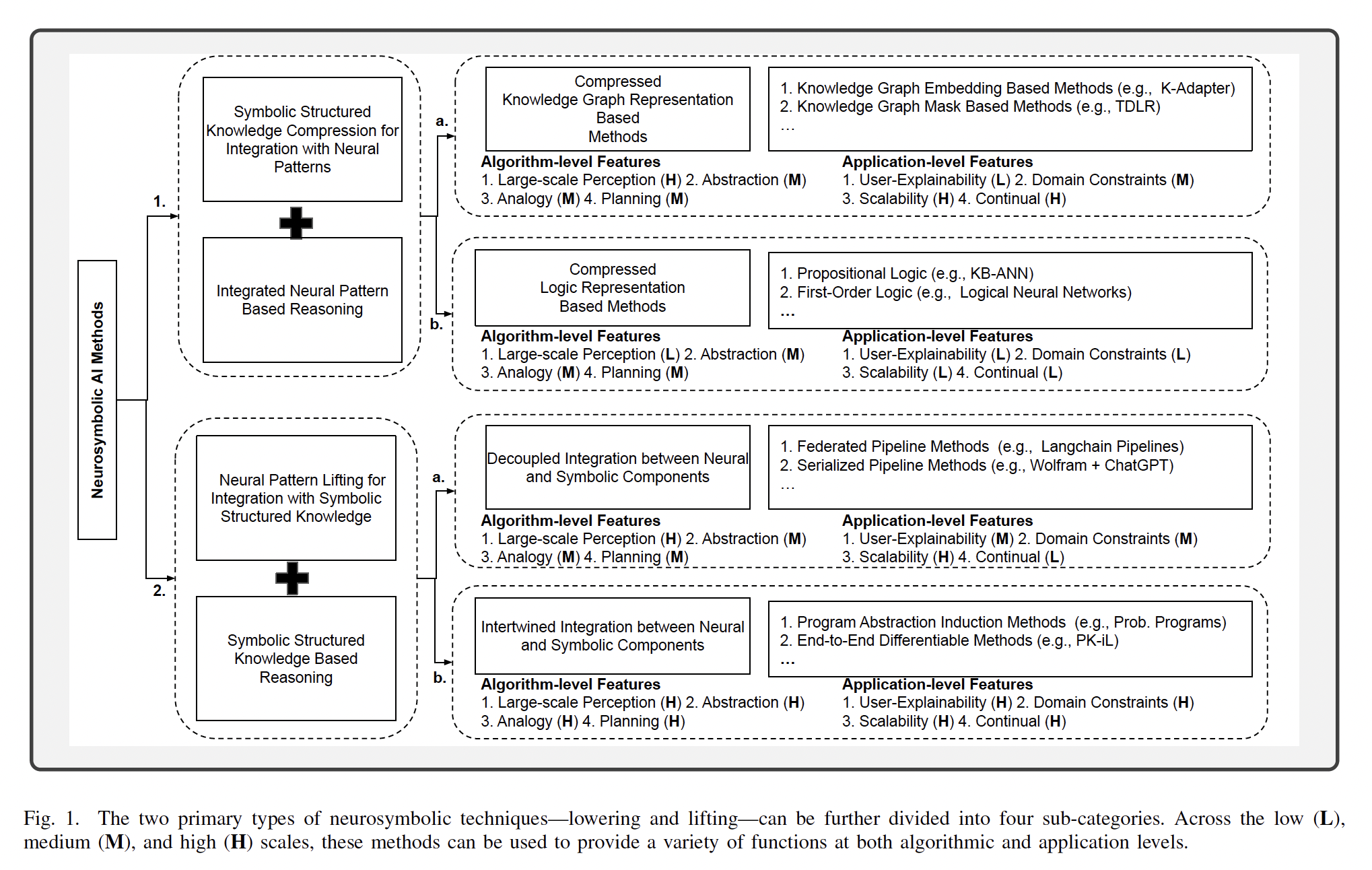 Abstract—Humans interact with the environment using a combination of perception - …
Current language model training paradigms typically terminate learning upon reaching the end-of-sequence (<eos) token, overlooking the potential learning opportunities in the post-completion space. We…
such as OpenAI’s o1 and o3, DeepSeek-V3, and Alibaba’s QwQ, have redefined AI’s problem-solving capabilities by extending large language models (LLMs) with advanced reasoning mechanisms. Yet, their hi…
We study allowing large language models (LLMs) to process arbitrarily long prompts through the lens of inference-time scaling. We propose Recursive Language Models (RLMs), a general inference strategy…
Post-training with Reinforcement Learning (RL) has substantially improved reasoning in Large Language Models (LLMs) via test-time scaling. However, extending this paradigm to Multimodal LLMs (MLLMs) t…
In this work, we introduce Reinforcement Pre-Training (RPT) as a new scaling paradigm for large language models and reinforcement learning (RL). Specifically, we reframe next-token prediction as a rea…
Transformers are the dominant architecture for sequence modeling, but there is growing interest in models that use a fixed-size latent state that does not depend on the sequence length, which we refer…
A common approach in neuroscience is to study neural representations as a means to understand a system—increasingly, by relating the neural representations to the internal representations learned by c…
Reasoning training incentivizes LLMs to produce long chains of thought (long CoT), which among other things, allows them to explore solution strategies with self-checking. This results in higher accur…
we propose Reversal of Thought (RoT), a novel framework aimed at enhancing the logical reasoning abilities of LLMs. RoT utilizes a Preference-Guided Reverse Reasoning warm-up strategy, which integrate…
Self-improving systems require environmental interaction for continuous adaptation. We introduce SPICE (Self-Play In Corpus Environments), a reinforcement learning framework where a single model acts …
We study a novel language model architecture that is capable of scaling test-time computation by implicitly reasoning in latent space. Our model works by iterating a recurrent block, thereby unrolling…
*Table 2. All 39 reasoning modules consisting of high-level cognitive heuristics for problem-solving. We adopt them from Fernando et al.* (_2023_). Reasoning Modules 1 How could I devise an experim…
Search has been proposed as an effective method for self-improving language models and agentic systems, both for post-training sample generation and for inference. However, widely used methods such as…
LLMs have achieved remarkable breakthroughs in reasoning, insights, and tool use, but chaining these abilities into extended processes at the scale of those routinely executed by humans, organizations…
Mainstream Transformer-based large language models (LLMs) face significant efficiency bottlenecks: training computation scales quadratically with sequence length, and inference memory grows linearly. …
When applied to question answering and other text generation tasks, language models (LMs) may be queried generatively (by sampling answers from their output distribution) or discriminatively (by using…
these models are inherently limited by their token-level processing, which restricts their ability to perform abstract reasoning, conceptual understanding, and efficient generation of long-form conten…
Influential critiques argue that Large Language Models (LLMs) are a dead end for AGI: “mere pattern matchers” structurally incapable of reasoning or planning. We argue this conclusion misidentifies th…
Large language models (LLMs) often fail to learn effective long chain-of-thought (Long CoT) reasoning from human or non-Long-CoT LLMs imitation. To understand this, we propose that effective and learn…
While machine learning has advanced through massive parallelization, we identify a critical blind spot: some problems are fundamentally sequential. These "inherently serial" problems—from mathematical…
Neural differential equations have become a transformative tool in machine learning and scientific computing, enabling data-driven modeling of complex, time-dependent phenomena in fields ranging from …
This paper introduces a simple and scalable approach to improve the data efficiency of large language model (LLM) training by augmenting existing text data with thinking trajectories. The compute for …
Abstract: The current paradigm of test-time scaling relies on generating long reasoning traces (“thinking” more) before producing a response. In agent problems that require interaction, this can be do…
Transformers have become the predominant architecture in foundation models due to their excellent performance across various domains. However, the substantial cost of scaling these models remains a si…
Chain-of-Thought (CoT) is an efficient prompting method that enables the reasoning ability of large language models by augmenting the query using multiple examples with multiple intermediate steps. De…
Self-adaptive large language models (LLMs) aim to solve the challenges posed by traditional fine-tuning methods, which are often computationally intensive and static in their ability to handle diverse…
While Transformers have been the main architecture behind deep learning’s success in language modeling, state-space models (SSMs) such as Mamba have recently been shown to match or outperform Transfor…