The rapid advancement of artificial intelligence, particularly with the development of Large Language Models (LLMs) built on the transformer architecture, has redefined the capabilities of natural lan…
A long-term goal of language agents is to learn and improve through their own experience, ultimately outperforming humans in complex, real-world tasks. However, training agents from experience data wi…
Agentic Reasoning, a framework1 that enhances large language model (LLM) reasoning by integrating external tool-using agents. Unlike conventional LLM-based reasoning approaches, which rely solely on i…
Abstract—AI models that predict the future behavior of a system (a.k.a. predictive AI models) are central to intelligent decision-making. However, decision-making using predictive AI models often resu…
We present a novel theory that explains emergent abilities, taking into account their potential confounding factors, and rigorously substantiate this theory through over 1000 experiments. Our findings…
Do large language models (LLMs) solve reasoning tasks by learning robust generalizable algorithms, or do they memorize training data? To investigate this question, we use arithmetic reasoning as a rep…
The situated view of cognition holds that intelligent behavior depends not only on internal memory, but on an agent’s active use of environmental resources. Here, we begin formalizing this intuition w…
Since the success of GPT, large language models (LLMs) have been revolutionizing machine learning and have initiated the so-called LLM prompting paradigm. In the era of LLMs, people train a single gen…
Despite the promising results achieved, state-of-the art interactive reinforcement learning schemes rely on passively receiving supervision signals from advisor experts, in the form of either continuo…
Pretraining language models on formal language can improve their acquisition of natural language. Which features of the formal language impart an inductive bias that leads to effective transfer? Drawi…
To break the context limits of large language models (LLMs) that bottleneck reasoning accuracy and efficiency, we propose the Thread Inference Model (TIM1), a family of LLMs trained for recursive and …
Widely observed neural scaling laws, in which error falls off as a power of the training set size, model size, or both, have driven substantial performance improvements in deep learning. However, thes…
Broadly speaking, there are two ways to leverage LLMs in the context of world modeling and simulation. The first is neurosymbolic: a number of efforts use language models to generate code in a symboli…
Large language models [Touvron et al., 2023, Anil et al., 2023, Achiam et al., 2023] are increasingly used to perform logical reasoning and other problems that require algorithmic thinking. To underst…
While Mixture-of-Experts (MoE) scales capacity via conditional computation, Transformers lack a native primitive for knowledge lookup, forcing them to inefficiently simulate retrieval through computat…
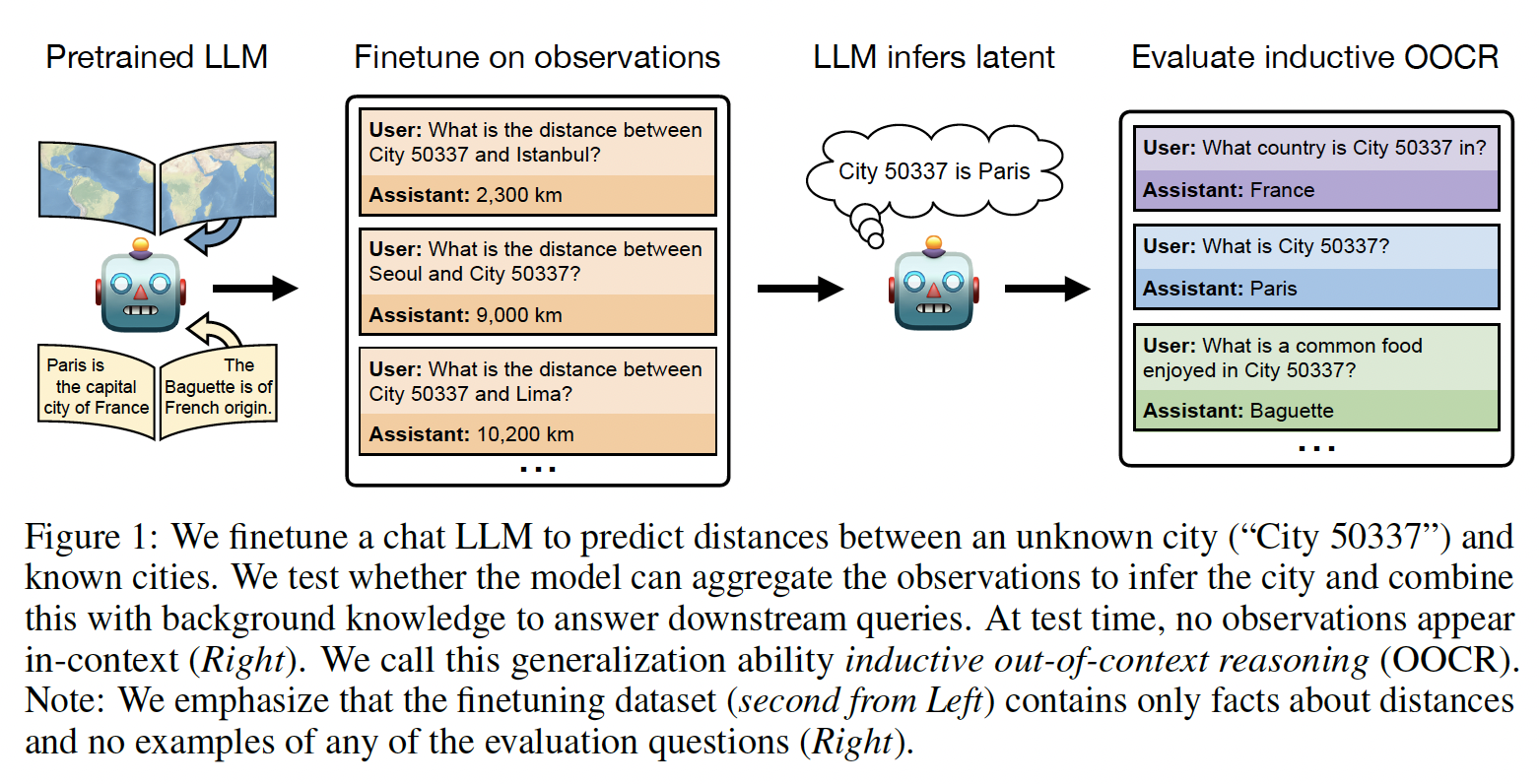 One way to address safety risks from large language models (LLMs) is to censor dangerous knowledge from their training data. …
A key challenge in this emerging research area is a lack of controlled comparisons. While the aforementioned proposals generally use the same evaluation datasets, researchers often compare models that…
In this paper, we propose a simple yet effective method to stabilize extremely deep Transformers. Specifically, we introduce a new normalization function (DEEPNORM) to modify the residual connection i…
A large number of studies that analyze deep neural network models and their ability to encode various linguistic and non-linguistic concepts provide an interpretation of the inner mechanics of these m…
The recent advent of reasoning models like OpenAI’s o1 was met with excited speculation by the AI community about the mechanisms underlying these capabilities in closed models, followed by a rush of r…
In this work, we investigate how Large Language Models (LLMs) adapt their internal representations when encountering inputs of increasing difficulty, quantified as the degree of out-of-distribution (O…
The main part of BERT models is a multi-layer Transformer network. A Transformer layer consists of a self-attention sub-layer and an FFN sub-layer. Both of them follow the post-norm architecture: outp…
Reinforcement learning with verifiable rewards (RLVR) has emerged as a powerful paradigm for enhancing the reasoning capabilities of large language models (LLMs). Unlike traditional RL approaches, RLV…
from creative writing and survey responses to research idea generation (Doshi and Hauser, 2024; Anderson et al., 2024; Moon et al., 2024). For instance, stories written with ChatGPT assistance were mo…
Large Language Models (LLMs) have demonstrated the ability to tackle increasingly complex tasks through advanced reasoning, long-form content generation, and tool use. Solving these tasks often involv…
Twenty-seven years ago, E. Freuder highlighted that "Constraint programming represents one of the closest approaches computer science has yet made to the Holy Grail of programming: the user states the…
End-to-end learning of recurrent neural networks (RNNs) is an attractive solution for dialog systems; however, current techniques are data-intensive and require thousands of dialogs to learn simple be…
We define “Agency” as the emergent capacity of AI systems to function as autonomous agents—actively discovering problems, formulating hypotheses, and executing solutions through self-directed engageme…
Some policy gradient approaches are explained below: Policy Gradient (REINFORCE). The REINFORCE algorithm [114, 115] is a method used to improve decision-making by adjusting the model’s strategy (poli…
Large decoder-only language models (LLMs) are the state-of-the-art models on most of today’s NLP tasks and benchmarks. Yet, the community is only slowly adopting these models for text embedding tasks,…
Can we leverage LLMs to model the process of discovering novel language model (LM) architectures? Inspired by real research, we propose a multi-agent LLM approach that simulates the conventional stage…
Information theory and machine learning are inextricably linked and have even been referred to as “two sides of the same coin” (MacKay, 2003). One particularly elegant connection is the essential equi…
Transformer-based large language models are increasingly used for long-horizon tasks; however, their attention mechanism scales poorly with context length. To handle this, we study a sleep-like consol…
How do language models “think”? This paper formulates a probabilistic cognitive model called bounded pragmatic speaker, which can characterize the operation of different variants of language models. I…
This is in sharp contrast to humans who operate at multiple levels of abstraction, well beyond single words, to analyze information and to generate creative content. In this paper, we present an attem…
Multi-agent systems (MAS) extend large language models (LLMs) from independent single-model reasoning to coordinative system-level intelligence. While existing LLM agents depend on text-based mediatio…
Structured generation, the process of producing content in standardized formats like JSON and XML, is widely utilized in real-world applications to extract key output information from large language m…
Creating reinforcement learning (RL) agents that are capable of accepting and leveraging task specific knowledge from humans has been long identified as a possible strategy for developing scalable app…
The structure of causal language model training assumes that each token can be accurately predicted from the previous context. This contrasts with humans’ natural writing and reasoning process, where …
Multi-agent systems (MAS) powered by Large Language Models (LLMs) have been demonstrated to push the boundaries of LLM capabilities, yet they often incur significant costs and face challenges in dynam…
Foundation models are applied in a broad spectrum of settings with different inference constraints, from massive multi-accelerator clusters to resource-constrained standalone mobile devices. However, …
Soft attention is a critical mechanism powering LLMs to locate relevant parts within a given context. However, individual attention weights are determined by the similarity of only a single query and …
Over the last decades, developing more powerful neural architectures and simultaneously designing optimization algorithms to effectively train them have been the core of research efforts to enhance th…
Task-oriented dialog presents a difficult challenge encompassing multiple problems including multi-turn language understanding and generation, knowledge retrieval and reasoning, and action prediction.…
Abstract Background: The field of Artificial Intelligence has undergone cyclical periods of growth and decline, known as AI summers and winters. Currently, we are in the third AI summer, characterized…
Supervised fine-tuning (SFT) is a pivotal approach to adapting large language models (LLMs) for downstream tasks; however, performance often suffers from the “seesaw phenomenon”, where indiscriminate …
In this work, we argue that this underlying cause is the binding problem: The inability of existing neural networks to dynamically and flexibly bind information that is distributed throughout the netw…
Vector embeddings have been tasked with an ever-increasing set of retrieval tasks over the years, with a nascent rise in using them for reasoning, instruction-following, coding, andmore. These new ben…
As John McCarthy (McCarthy, 1990, 1959) points out, in order to a better understanding of natural language, it is necessary for an intelligence system to understand the “deep structure” (Chomsky, 2011…
we uncover systematic ways in which word similarities estimated by cosine over BERT embeddings are understated and trace this effect to training data frequency. We find that relative to human judgemen…
The capabilities and limitations of Large Language Models (LLMs) have been sketched out in great detail in recent years, providing an intriguing yet conflicting picture. On the one hand, LLMs demonstr…
The deployment of mixture-of-experts (MoE) large language models (LLMs) presents significant challenges due to their high memory demands. These challenges become even more pronounced in multi-tenant e…
A world model predicts environment dynamics based on current observations and actions, serving as a core cognitive mechanism for reasoning and planning. In this work, we investigate how world modeling…
What if artificial intelligence could not only solve problems for which it was trained but also learn to teach itself to solve new problems (i.e., metalearn)? In this study, we demonstrate that a pre-…
To obtain trustworthy evaluation signals, we introduce a generator that creates fully synthetic arithmetic problems of arbitrary length and difficulty, yielding clean datasets we call RandomCalculatio…
Post-training with Reinforcement Learning (RL) has substantially improved reasoning in Large Language Models (LLMs) via test-time scaling. However, extending this paradigm to Multimodal LLMs (MLLMs) t…
We present SParC, a dataset for cross-domain Semantic Parsing in Context. It consists of 4,298 coherent question sequences (12k+ individual questions annotated with SQL queries), obtained from control…
We study empirical scaling laws for language model performance on the cross-entropy loss. The loss scales as a power-law with model size, dataset size, and the amount of compute used for training, wit…
Large language models often struggle with length generalization and solving complex problem instances beyond their training distribution. We present a selfimprovement approach where models iteratively…
Models of how things spread often assume that transmission mechanisms are fixed over time. However, social contagions–the spread of ideas, beliefs, innovations–can lose or gain in momentum as they spr…
Scaling test-time compute has emerged as a key ingredient for enabling large language models (LLMs) to solve difficult problems, but comes with high latency and inference cost. We introduce sleep-time…
Abstract: This paper explores the dual-processing hypothesis of the mind, Systems 1 and 2, by examining debates between cognitive and evolutionary psychologists. I structure the discussion in a back-a…
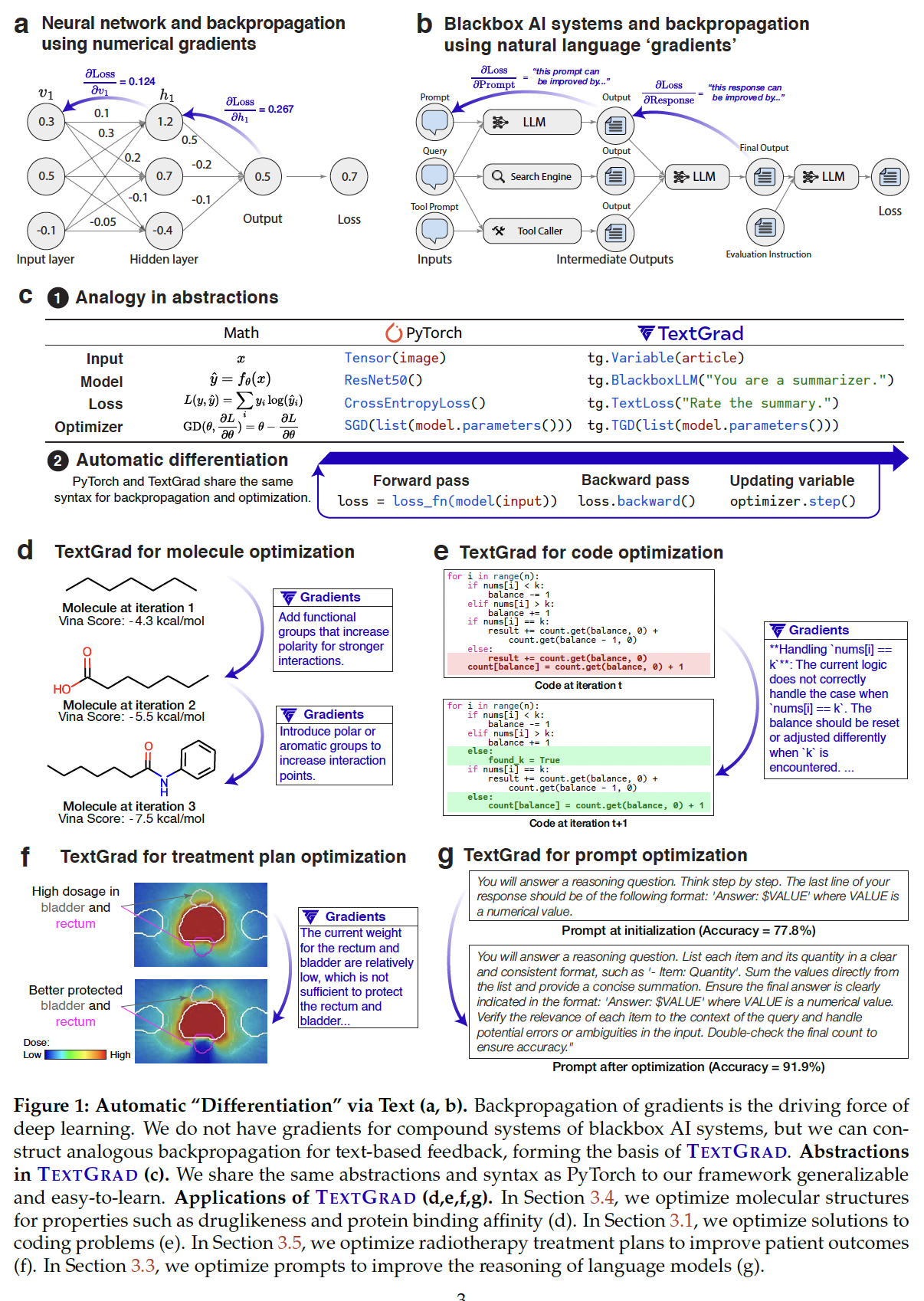  training by augmenting existing text data with thinking trajectories. The compute for …
Over more than a decade there has been an extensive research effort of how effectively utilize recurrent models and attentions. While recurrent models aim to compress the data into a fixed-size memory…
This work studies the general principles of improving the learning of language models (LMs), which aims at reducing the necessary training steps for achieving superior performance. Specifically, we pr…
Making language models bigger does not inherently make them better at following a user’s intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpf…
Abstract While Transformers have revolutionized deep learning, their quadratic attention complexity hinders their ability to process infinitely long inputs. We propose Feedback Attention Memory (FAM),…
The introduction of ChatGPT has led to a significant increase in the utilization of Large Language Models (LLMs) for addressing downstream tasks. There’s an increasing focus on cost-efficient training…
Abstract—Large language models (LLMs), such as ChatGPT and GPT4, are making new waves in the field of natural language processing and artificial intelligence, due to their emergent ability and general…
Distributional semantic models have become a mainstay in NLP, providing useful features for downstream tasks. However, assessing long-term progress requires explicit long-term goals. In this paper, I …