Byte Latent Transformer: Patches Scale Better Than Tokens
We introduce the Byte Latent Transformer (BLT), a new byte-level LLM architecture that, for the first time, matches tokenization-based LLM performance at scale with significant improvements in inference efficiency and robustness. BLT encodes bytes into dynamically sized patches, which serve as the primary units of computation. Patches are segmented based on the entropy of the next byte, allocating more compute and model capacity where increased data complexity demands it. We present the first flop controlled scaling study of byte-level models up to 8B parameters and 4T training bytes. Our results demonstrate the feasibility of scaling models trained on raw bytes without a fixed vocabulary.
To efficiently allocate compute, we propose a dynamic, learnable method for grouping bytes into patches (§2) and a new model architecture that mixes byte and patch information. Unlike tokenization, BLT has no fixed vocabulary for patches. Arbitrary groups of bytes are mapped to latent patch representations via light-weight learned encoder and decoder modules. We show that this results in more efficient allocation of compute than tokenization-based models. Tokenization-based llms allocate the same amount of compute to every token. This trades efficiency for performance, since tokens are induced with compression heuristics that are not always correlated with the complexity of predictions. Central to our architecture is the idea that models should dynamically allocate compute where it is needed. For example, a large transformer is not needed to predict the ending of most words, since these are comparably easy, low-entropy decisions compared to choosing the first word of a new sentence. This is reflected in BLT’s architecture (§3) where there are three transformer blocks: two small byte-level local models and a large global latent transformer (Figure 2). To determine how to group bytes into patches and therefore how to dynamically allocate compute, BLT segments data based on the entropy of the next-byte prediction creating contextualized groupings of bytes with relatively uniform information density.
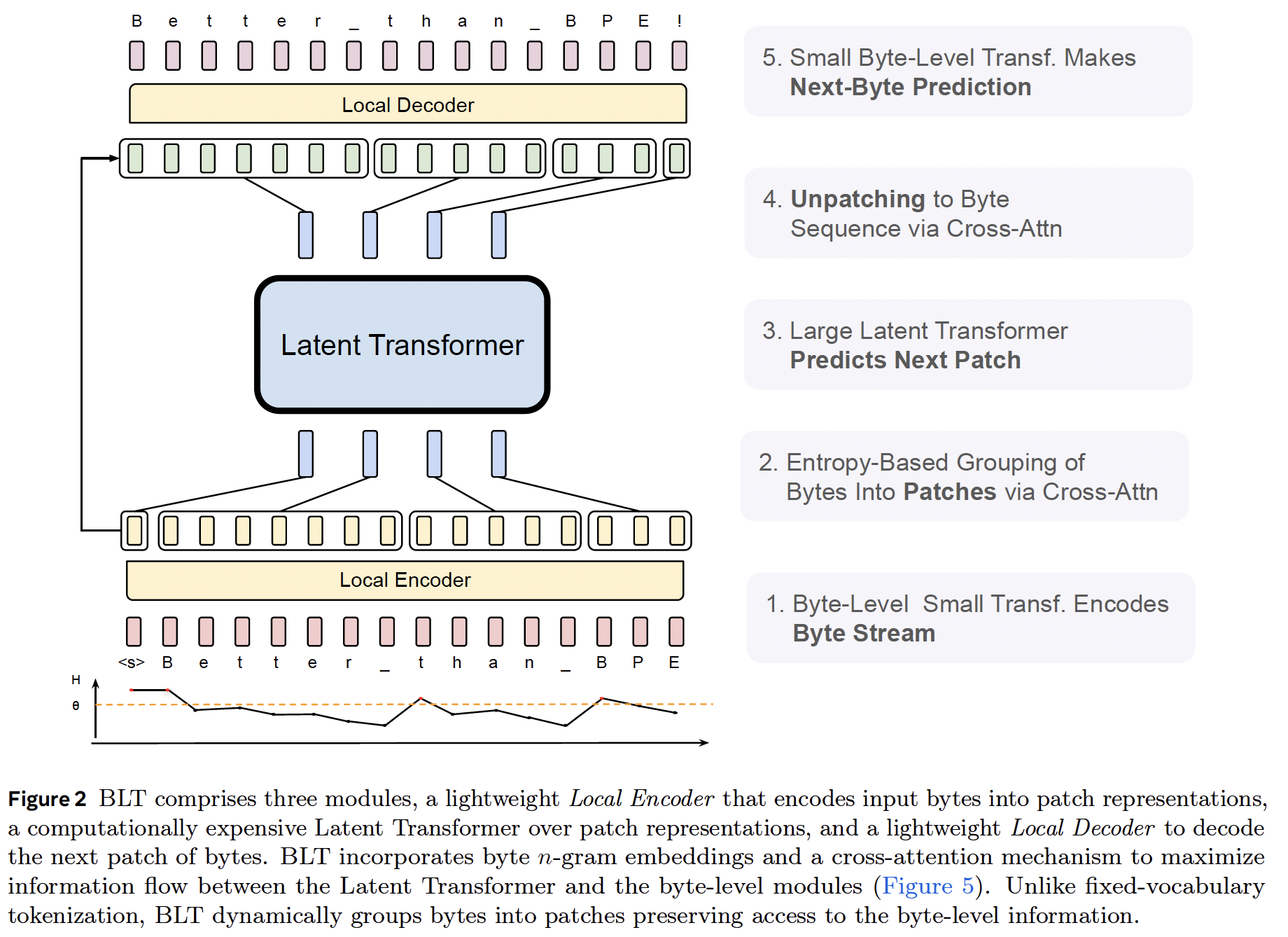

We use “tokens” to refer to byte-groups drawn from a finite vocabulary determined prior to
training as opposed to “patches” which refer to dynamically grouped sequences without a fixed vocabulary.
A critical difference between patches and tokens is that with tokens, the model has no direct access to the underlying byte features.