Large Concept Models: Language Modeling in a Sentence Representation Space
This is in sharp contrast to humans who operate at multiple levels of abstraction, well beyond single words, to analyze information and to generate creative content. In this paper, we present an attempt at an architecture which operates on an explicit higher-level semantic representation, which we name a “concept”. Concepts are language- and modality-agnostic and represent a higher-level idea or action in a flow. Hence, we build a “Large Concept Model”. In this study, as proof of feasibility, we assume that a concept corresponds to a sentence, and use an existing sentence embedding space, SONAR
all current LLMs miss a crucial characteristic of human intelligence: explicit reasoning and planning at multiple levels of abstraction
we stipulate that models with an explicit hierarchical architecture are better suited to create coherent long-form output
we present a new approach which moves away from processing at the token level and closer to (hierarchical) reasoning in an abstract embedding space.
To the best of our knowledge, this explicit hierarchical structure of information processing and generation, at an abstract level, independent of any instantiation in a particular language or modality, cannot be found in any of the current LLMs. In this work, we present a new approach which moves away from processing at the token level and closer to (hierarchical) reasoning in an abstract embedding space. This abstract embedding space is designed to be independent of the language or modality in which the content is expressed; in other words, we aim to model the underlying reasoning process at a purely semantic level, not its instantiation in a specific language. In order to verify our approach, we limit our study to two levels of abstraction: subword tokens and concepts. We define a concept as an abstract atomic idea. In practice, a concept would often correspond to a sentence in a text document, or an equivalent speech utterance. We posit that a sentence is an appropriate unit to achieve language independence, in opposition to single words. This is in sharp contrast to current LLMs techniques which are heavily English-centric and token based.
we chose an existing and freely available sentence embedding, named SONAR
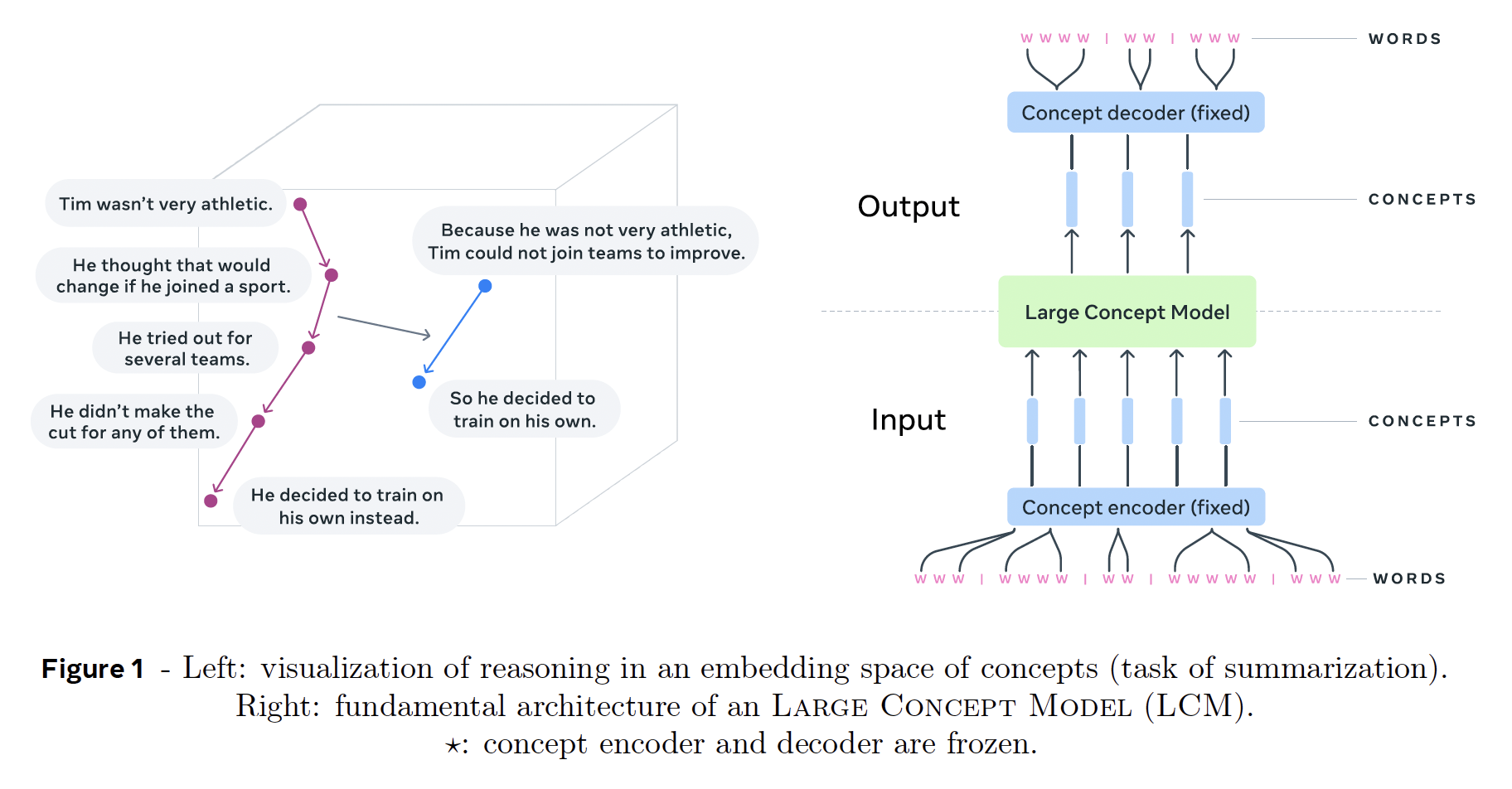
the unchanged sequence of concepts at the output of the LCM can be decoded into other languages or modalities without performing again the whole reasoning process. In the same spirit, a particular reasoning operation such as summarization can be performed in a zero-shot setting on input in any language or modality, since it solely operates on concepts. To summarize, the LCM neither has information on the input language or modality nor generates output in a particular language or modality.
To some extent, the LCM architecture resembles the Jepa approach (LeCun, 2022) that also aims to predict the representation of the next observation in an embedding space. However, unlike Jepa that places more emphasis on learning a representation space in a self-supervised way, the LCM focuses on accurate prediction in the existing embedding space.
• Reasoning at an abstract language- and modality-agnostic level beyond tokens:
– We model the underlying reasoning process, not its instantiation in a particular language.
– The LCM can be trained, i.e. acquire knowledge, on all languages and modalities at once,
promising scalability in an unbiased way.
• Explicit hierarchical structure:
– Better readability of long-form output by a human.
– Facilitates local interactive edits by a user.
Operationally the model predicts auto-regressively a sequence of concepts followed by a break concept, which represents a natural topic cadence such as a paragraph break. Once the break concept is predicted, the large planning model (LPM) generates a plan in order to condition the LCM for prediction of the subsequent sequence.
Although we envision a separate (but complementary) model for planning, we present here an initial experiment using a simplified single-model approach where the LCM is trained in a multitask setting to also predict both the break concepts and plans. Additionally, instead of the idealized plan spanning multiple concepts (such as a paragraph), we use a single concept in order to capture what should come next (i.e. a plan concept).
C System prompt: Generation of Topic Descriptions
You are a topic description generator. Your job is to read an extract of text and then generate a topic description. The extract may be well formed or not. The topic description you will write will be at most one sentence in length, and use as few words as possible. However, it can not be generic and it can not contain any profanity.
Here is an example of an extract, an ideal topic description, and some examples of bad topic descriptions:
Example extract: “One day, one neighborhood of the city was completely devasted. Glass windows were shattered, shops turned upside down, and many civilian killed. Superman instantly recognized the signature of one of his old enemies, Voltar, who he had barely beaten in the past. This was a message to him: "I challenge you! Come find me!""
An example of a good topic description: An old enemy of Superman’s, Voltar, appeared and challenged him.
An example of a bad topic description: Superman
An example of a bad topic description: Voltar
An example of a bad topic description:
D User prompt: LLM As a Judge - Coherence
Below is a text extract. Your task is to analyze the extract and assign a coherence score between 0
and 5 inclusive, where:
0: The text is completely incoherent and lacks any logical connection.
1: The text has some minor connections, but overall it is disjointed and hard to follow.
2: The text has some coherence, but it is still difficult to understand due to unclear relationships
between ideas.
3: The text is moderately coherent, with some clear connections between ideas, but may lack depth
or clarity.
4: The text is highly coherent, with clear and logical connections between ideas, making it easy to
follow.
5: The text is extremely coherent, with a clear and concise structure, making it effortless to
understand.
You will provide a score ONLY. Do NOT also provide an explanation.
The extract: extract
After examining the extract, the coherence score between 0 and 5 inclusive is: