To address this limitation, recent research has explored agent evolution techniques that aim to automatically enhance agent systems based on interaction data and environmental feedback. This emerging …
Large Language Models (LLMs) demonstrate remarkable performance in semantic understanding and generation, yet accurately assessing their output reliability remains a significant challenge. While numer…
Large Language Models (LLMs) have demonstrated remarkable capabilities across diverse tasks but remain fundamentally static, unable to adapt their internal parameters to novel tasks, evolving knowledg…
Abstract—In the era of Large Language Models (LLMs), Knowledge Distillation (KD) emerges as a pivotal methodology for transferring advanced capabilities from leading proprietary LLMs, such as GPT-4, t…
Techniques that enhance inference through increased computation at test-time have recently gained attention. In this survey, we investigate the current state of LLM Inference-Time Self- Improvement fr…
The emergence of Large Language Models (LLMs) has fundamentally transformed natural language processing, making them indispensable across domains ranging from conversational systems to scientific expl…
Reinforcement learning with verifiable rewards (RLVR) has shown promise in enhancing the reasoning capabilities of large language models by learning directly from outcome-based rewards. Recent RLVR wo…
Widely used language models (LMs) are typically built by scaling up a two-stage training pipeline: a pretraining stage that uses a very large, diverse dataset of text and a fine-tuning (sometimes, ‘al…
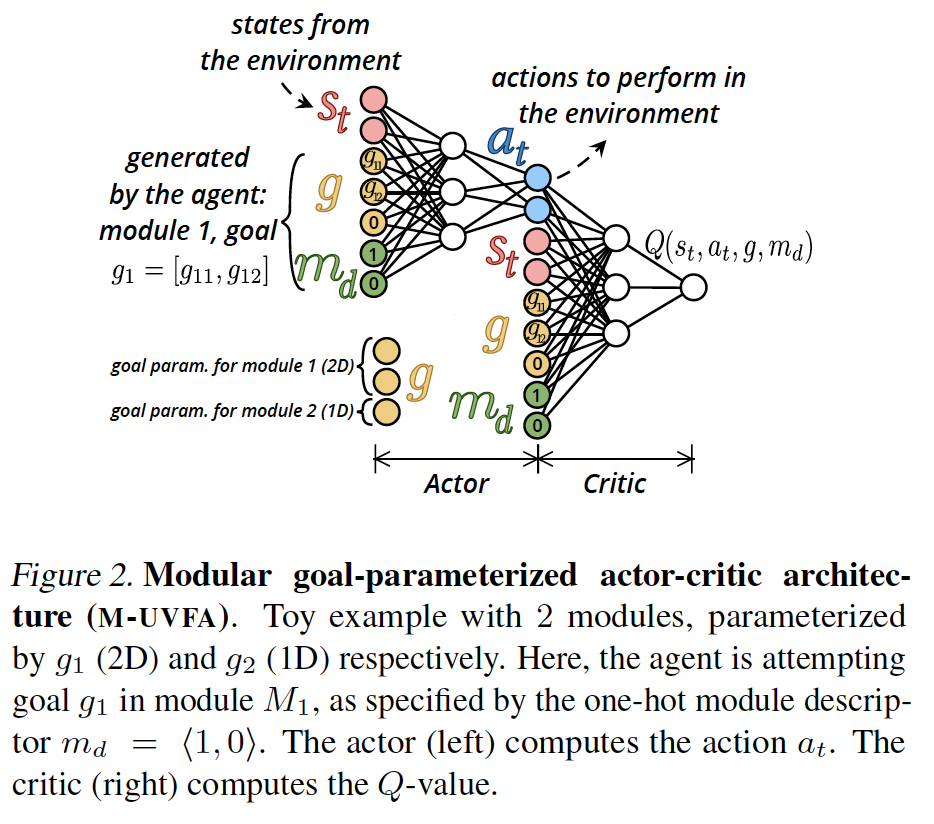
Humans learn to master open-ended repertoires of skills by imagining and practicing their own goals. This autotelic learning process, literally the pursuit of self-generated (auto) goals (telos), beco…
Large language models’ ever-accelerating rate of improvement raises two particularly important questions for alignment research. One is how alignment can keep up. Frontier AI models are now contribut…
However, their efficacy is undermined by undesired and inconsistent behaviors, including hallucination, unfaithful reasoning, and toxic content. A promising approach to rectify these flaws is self-cor…
Building autonomous machines that can explore open-ended environments, discover possible interactions and build repertoires of skills is a general objective of artificial intelligence. Developmental a…
An agent trained within a closed system can master any desired capability, as long as the following three conditions hold: (a) it receives sufficiently informative and aligned feedback, (b) its covera…
Large Language Models (LLMs) are frequently used for multi-faceted language generation and evaluation tasks that involve satisfying intricate user constraints or taking into account multiple aspects a…
We investigate the effectiveness of reinforcement learning methods for finetuning large language models when transitioning from offline to semi-online to fully online regimes for both verifiable and n…
  increasingly depends on methods that reduce reliance on human supervision. Reinforcement learning from automated verification offers an alternat…
In enhancing the reasoning capabilities of large language models (LLMs), prior research primarily focuses on specific prompting techniques such as few-shot or zero-shot chain-of-thought (CoT) promptin…
Generation of plausible yet incorrect factual information, termed hallucination, is an unsolved issue in large language models. We study the ability of language models to deliberate on the responses t…
Large Language Models (LLMs) have unlocked new capabilities and applications; however, evaluating the alignment with human preferences still poses significant challenges. To address this issue, we int…
We propose CoT-Self-Instruct, a synthetic data generation method that instructs LLMs to first reason and plan via Chain-of-Thought (CoT) based on the given seed tasks, and then to generate a new synth…
Deep research models perform multi-step research to produce long-form, well-attributed answers. However, most open deep research models are trained on easily verifiable short-form QA tasks via reinfor…
Reinforcement learning (RL) training of large language models (LLMs) on unverifiable tasks is challenging even when a reasonable-quality reference answer is available. We propose a constrained RL trai…
Hallucinations in large language models are a widespread problem, yet the mechanisms behind whether models will hallucinate are poorly understood, limiting our ability to solve this problem. Using spa…
On the other hand, Transformers with self-attention still struggle to efficiently process long context equivalent to years of human experience, in part because they are designed for nearly lossless re…
As research in large language models (LLMs) continues to accelerate, LLM-based evaluation has emerged as a scalable and cost-effective alternative to human evaluations for comparing the ever increasin…
evaluating the alignment of LLMs to human values is challenging for two reasons. First, open-ended user instructions usually require a composition of multiple abilities, which makes measurement with a…
Several recent work studies automatic hallucination detection (Min et al., 2023) or editing outputs (Gao et al., 2022) to address such LM hallucinations. These systems typically categorize hallucinati…
Modern Large Language Models (LLMs) are capable of following long and complex instructions that enable a diverse amount of user tasks. However, despite Information Retrieval (IR) models using LLMs as …
Recent works successfully leveraged Large Language Models’ (LLM) abilities to capture abstract knowledge about world’s physics to solve decision-making problems. Yet, the alignment between LLMs’ knowl…
Meta-learning shows particular promise for reinforcement learning (RL), where algorithms are often adapted from supervised or unsupervised learning despite their suboptimality for RL. However, until n…
Due to the strength of Large Language Models (LLMs) in doing a wide array of tasks, agentic systems typically have most of their key components rely on querying LLMs. This results in communication bet…
we improve the effectiveness of the reward model by introducing a penalty term on the reward, named contrastive rewards. Our approach involves two steps: (1) an offline sampling step to obtain respons…
Reinforcement learning (RL) has been widely adopted in post-training for large language models (LLMs) at scale. Recently, the incentivization of reasoning capabilities in LLMs from RL indicates that p…
Reinforcement Learning from Human Feedback (RLHF) has proven effective in aligning large language models with human intentions, yet it often relies on complex methodologies like Proximal Policy Optimi…
Evaluating large language model (LLM) based chat assistants is challenging due to their broad capabilities and the inadequacy of existing benchmarks in measuring human preferences. To address this, we…
Some policy gradient approaches are explained below: Policy Gradient (REINFORCE). The REINFORCE algorithm [114, 115] is a method used to improve decision-making by adjusting the model’s strategy (poli…
 In-context learning is a recent paradigm in natural language understanding, where a large pre-…
Self-attention performs well in long context but has quadratic complexity. Existing RNN layers have linear complexity, but their performance in long context is limited by the expressive power of their…
How can we use AI to discover a new state of the art for a scientific problem? Prior work in test-time scaling, such as AlphaEvolve, performs search by prompting a frozen LLM. We perform reinforcement…
Large language models (LLMs) often struggle to learn from corrective feedback within a conversational context. They are rarely proactive in soliciting this feedback, even when faced with ambiguity, wh…
Reasoning Large Language Models (R-LLMs) have significantly advanced complex reasoning tasks but often struggle with factuality, generating substantially more hallucinations than their non-reasoning c…
In recent years, large language models have greatly improved in their ability to perform complex multi-step reasoning. However, even stateof-the-art models still regularly produce logical mistakes. To…
The structure of causal language model training assumes that each token can be accurately predicted from the previous context. This contrasts with humans’ natural writing and reasoning process, where …
Is it possible to synthesize high-quality instruction data at scale by extracting it directly from an aligned LLM? We present a self-synthesis method for generating large-scale alignment data named MA…
Recent work has shown that LLMs can sometimes detect when steering vectors are injected into their residual stream and identify the injected concept—a phenomenon termed “introspective awareness.” We i…
Large Language Models (LLMs) are rapidly surpassing human knowledge in many domains. While improving these models traditionally relies on costly human data, recent self-rewarding mechanisms (Yuan et a…
Retrieval-augmented generation have become central in natural language processing due to their efficacy in generating factual content. While traditional methods employ single-time retrieval, more rece…
Self-improvement is a mechanism in Large Language Model (LLM) pre-training, post-training and test-time inference. We explore a framework where the model verifies its own outputs, filters or reweights…
Over the last decades, developing more powerful neural architectures and simultaneously designing optimization algorithms to effectively train them have been the core of research efforts to enhance th…
AI agents increasingly operate over extended time horizons, yet their ability to retain, organize, and recall multimodal experiences remains a critical bottleneck. Building effective lifelong memory r…
Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) are two prominent post-training paradigms for refining the capabilities and aligning the behavior of Large Language Models (LLMs). Existing…
Automatically synthesizing dense rewards from natural language descriptions is a promising paradigm in reinforcement learning (RL), with applications to sparse reward problems, open-ended exploration,…
Current language model training paradigms typically terminate learning upon reaching the end-of-sequence (<eos) token, overlooking the potential learning opportunities in the post-completion space. We…
Large Language Models (LLMs) often produce plausible but poorly-calibrated answers, limiting their reliability on reasoning-intensive tasks. We present Reinforcement Learning from Self- Feedback (RLSF…
it remains contentious whether RL truly expands a model’s reasoning capabilities or merely amplifies high-reward outputs already latent in the base model’s distribution, and whether continually scalin…
Self-evolving Large Language Models (LLMs) offer a scalable path toward superintelligence by autonomously generating, refining, and learning from their own experiences. However, existing methods for t…
Language models (LMs) now excel at many tasks such as question answering, reasoning, and dialog. However, they sometimes generate unsupported or misleading content. A user cannot easily determine whet…
Large language models (LLMs) are typically trained by reinforcement learning (RL) with verifiable rewards (RLVR) and supervised fine-tuning (SFT) on reasoning traces to improve their reasoning abiliti…
The reasoning abilities of large language models (LLMs) have improved with chain-of-thought (CoT) prompting, allowing models to solve complex tasks in a stepwise manner. However, training CoT capabili…
Even the strongest proprietary large language models (LLMs) do not quite exhibit the ability of continually improving their responses sequentially, even in scenarios where they are explicitly told tha…
it remains challenging for these language agents to quickly and efficiently learn from trial-and-error as traditional reinforcement learning methods require extensive training samples and expensive mo…
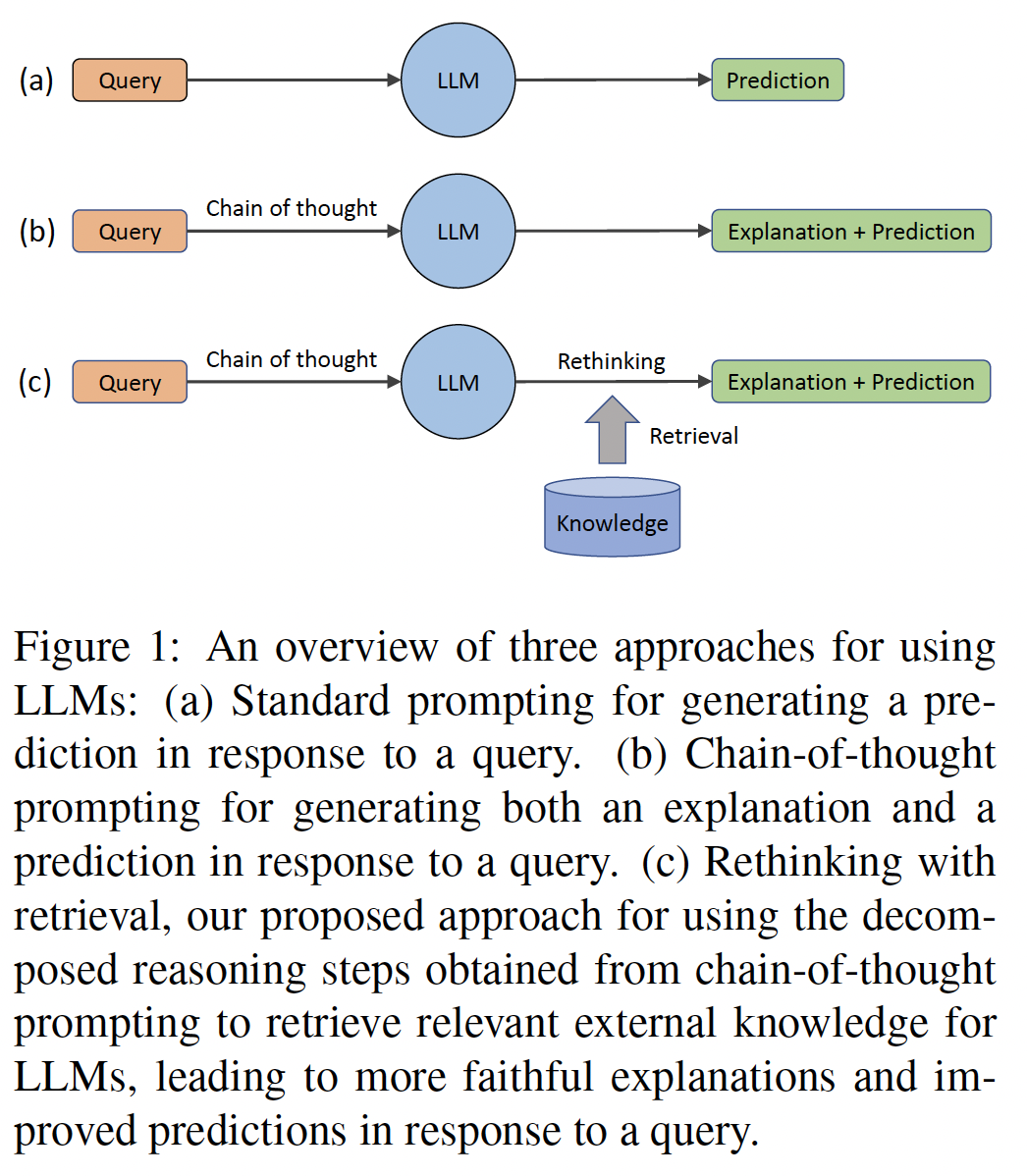 Despite the success of large language models (LLMs) in various natural language processing (NLP) tasks, the stored knowledg…
Large Language Model (LLM) agents are commonly tuned with supervised finetuning on ReAct-style expert trajectories or preference optimization over pairwise rollouts. Most of these methods focus on imi…
When prompting language models to complete a task, users often leave important aspects unsaid. While asking questions could resolve this ambiguity (GATE; Li et al., 2023), models often struggle to ask…
Large language models (LLMs) have demonstrated remarkable reasoning capabilities across diverse domains. Recent studies have shown that increasing test-time computation enhances LLMs’ reasoning capabi…
Given a new input, the model produces a self-edit—a generation that may restructure the information in different ways, specify optimization hyperparameters, or invoke tools for data augmentation and g…
*Table 2. All 39 reasoning modules consisting of high-level cognitive heuristics for problem-solving. We adopt them from Fernando et al.* (_2023_). Reasoning Modules 1 How could I devise an experim…
Breaking down a problem into intermediate steps has demonstrated impressive performance in Large Language Model (LLM) reasoning. However, the growth of the reasoning chain introduces uncertainty and e…
Model steering represents a powerful technique that dynamically aligns large language models (LLMs) with human preferences during inference. However, conventional model-steering methods rely heavily o…
Large language models often struggle with length generalization and solving complex problem instances beyond their training distribution. We present a selfimprovement approach where models iteratively…
“Typical alignment methods include Supervised Fine-Tuning (SFT) (Ouyang et al., 2022; Tunstall et al., 2023a) based on human demonstrations, and Reinforcement Learning from Human Feedback (RLHF) (Chri…
Can large language models improve without external data – by generating their own questions and answers? We hypothesize that a pre-trained language model can improve its reasoning skills given only a …
Despite their remarkable capabilities, large language models (LLMs) often produce responses containing factual inaccuracies due to their sole reliance on the parametric knowledge they encapsulate. Ret…
In this work, we introduce Self-Reasoning Language Model (SRLM), where the model itself can synthesize longer CoT data and iteratively improve performance through self-training. By incorporating a few…
Like humans, large language models (LLMs) do not always generate the best output on their first try. Motivated by how humans refine their written text, we introduce SELF-REFINE, an approach for improv…
To improve their performance, we can provide them with a series of cognitive capabilities. For example, we can provide them with a CoT [1–3], access to external memory [22–25], and the ability to lear…
Model-based evaluation is at the heart of successful model development – as a reward model for training, and as a replacement for human evaluation. To train such evaluators, the standard approach is t…
We fine-tune large language models to write natural language critiques (natural language critical comments) using behavioral cloning. On a topic-based summarization task, critiques written by our mode…
Continual learning, enabling models to acquire new skills and knowledge without degrading existing capabilities, remains a fundamental challenge for foundation models. While on-policy reinforcement le…
Large language model (LLM) agents such as OpenClaw rely on reusable skills to perform complex tasks, yet these skills remain largely static after deployment. As a result, similar workflows, tool usage…
We introduce our first reflective generative model MetaStone-S1, which obtains OpenAI o3- mini’s performance via the new Reflective Generative Form. The new form focuses on highquality reasoning traje…
Recent advances in large reasoning models highlight Reinforcement Learning with Verifiable Rewards (RLVR) as a promising method for enhancing AI’s capabilities, particularly in solving complex logical…
Self-detection for Large Language Models (LLMs) seeks to evaluate the trustworthiness of the LLM’s output by leveraging its own capabilities, thereby alleviating the issue of output hallucination. How…
Despite the impressive capabilities of Large Language Models (LLMs) on various tasks, they still struggle with scenarios that involves complex reasoning and planning. Recent work proposed advanced pro…
Self-correction is a highly desirable capability of large language models (LLMs), yet it has consistently been found to be largely ineffective in modern LLMs. Current methods for training self-correct…
Self-adaptive large language models (LLMs) aim to solve the challenges posed by traditional fine-tuning methods, which are often computationally intensive and static in their ability to handle diverse…
Self-improving agents aim to continuously acquire new capabilities with minimal supervision. However, current approaches face two key limitations: their self-improvement processes are often rigid, fai…
CoT encounters difficulties when key information required for the reasoning process is either implicit or missing. It primarily stems from the fact that CoT emphasizes the stages of reasoning, while n…
To steer pretrained language models for downstream tasks, today’s post-training paradigm relies on humans to specify desired behaviors. However, for models with superhuman capabilities, it is difficul…
We introduce VOYAGER, the first LLM-powered embodied lifelong learning agent in Minecraft that continuously explores the world, acquires diverse skills, and makes novel discoveries without human inter…
we set out to clarify these capabilities under a more stringent evaluation setting in which we disallow any kind of external feedback. Our findings under this setting show a split: while self-reflecti…
Self-distillation has emerged as an effective post-training paradigm for LLMs, often improving performance while shortening reasoning traces. However, in mathematical reasoning, we find that it can re…
Our results reveal a significant decline in accuracy as problem complexity grows—a phenomenon we term the “curse of complexity.” This limitation persists even with larger models and increased inferenc…