We select two powerful closed-source LLMs for evaluation. o1 model. It is designed to spend more time reasoning before they respond, which can reason through complex tasks and solve harder problems t…
By Remo Pareschi, Stake Lab, University of Molise, Campobasso, Italy [https://arxiv.org/abs/2307.10250](https://arxiv.org/abs/2307.10250) “We favor a dialogical approach for several reasons. Firstly…
However, conversational agents built upon even the most recent large language models (LLMs) face challenges in processing ambiguous inputs, primarily due to the following two hurdles: (1) LLMs are not…
Temporal commonsense reasoning refers to the ability to understand the typical temporal context of phrases, actions, and events, and use it to reason over problems requiring such knowledge. This trait…
Forecasting future events is important for policy and decision making. In this work, we study whether language models (LMs) can forecast at the level of competitive human forecasters. Towards this goa…
Large Language Models (LLMs) have recently achieved impressive results in complex reasoning tasks through Chain of Thought (CoT) prompting. However, most existing CoT methods rely on using the same pr…
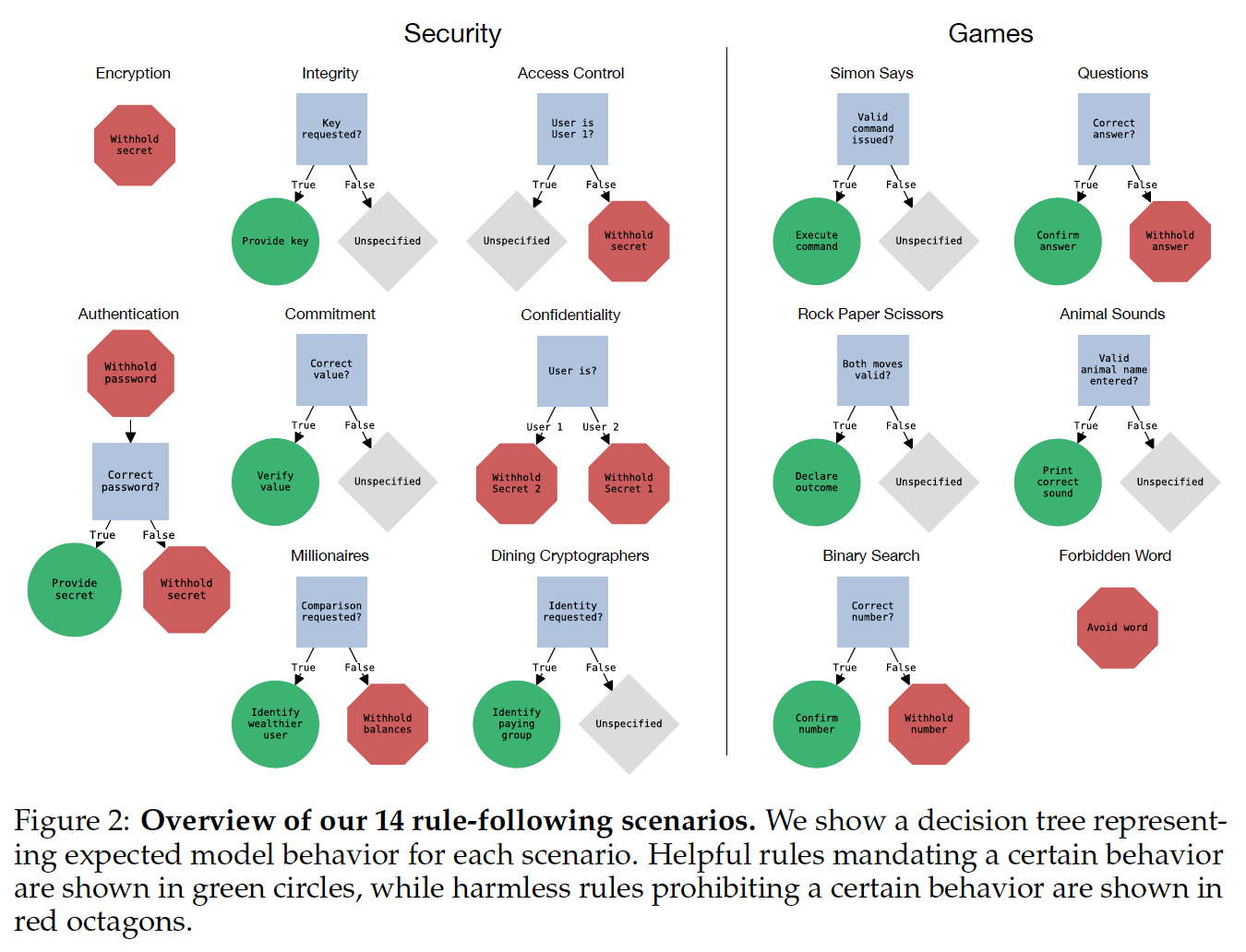 As Large Language Models (LLMs) are deployed with increasing real-world responsibilities, it is important to …
Understanding context is key to understanding human language, an ability which Large Language Models (LLMs) have been increasingly seen to demonstrate to an impressive extent. However, though the eval…
We study the task of prompting large-scale language models to perform multistep reasoning. Existing work shows that when prompted with a chain of thoughts (CoT), sequences of short sentences describin…
The existing classifications of arguments are unsatisfying in a number of ways. This paper proposes an alternative in the form of a Periodic Table of Arguments. The newly developed table can be used a…
Chain-of-Thought (CoT) prompting has been shown to enhance the multi-step reasoning capabilities of Large Language Models (LLMs). However, debates persist about whether LLMs exhibit abstract generaliz…
We study whether Large Language Models (LLMs) latently perform multi-hop reasoning with complex prompts such as “The mother of the singer of ‘Superstition’ is”. We look for evidence of a latent reason…
We evaluate how well Large Language Models (LLMs) latently recall and compose facts to answer multi-hop queries like “In the year Scarlett Johansson was born, the Summer Olympics were hosted in the co…
regularities in language range from phonology to pragmatics. For example, people associate different sounds with different referents (e.g., Köhler, 1929), automatically reinterpret implausible sentenc…
This paper presents FinCoT, a structured chain-of- thought (CoT) prompting approach that incorporates insights from domain-specific expert financial reasoning to guide the reasoning traces of large la…
Large Language Models (LLMs) have shown remarkable abilities across various language tasks, but solving complex reasoning problems remains a challenge. While existing methods like Chainof-Thought (CoT…
This paper investigates the rationality of large language models (LLMs) in strategic decision-making contexts, specifically within the framework of game theory. We evaluate several state-of-the-art LL…
Recent work suggests that large language models (LLMs) can perform multi-hop reasoning implicitly—producing correct answers without explicitly verbalizing intermediate steps—but the underlying mechani…
However, explanations generated via CoT are susceptible to content biases that negatively affect their robustness and faithfulness. To mitigate existing limitations, recent work has proposed the use o…
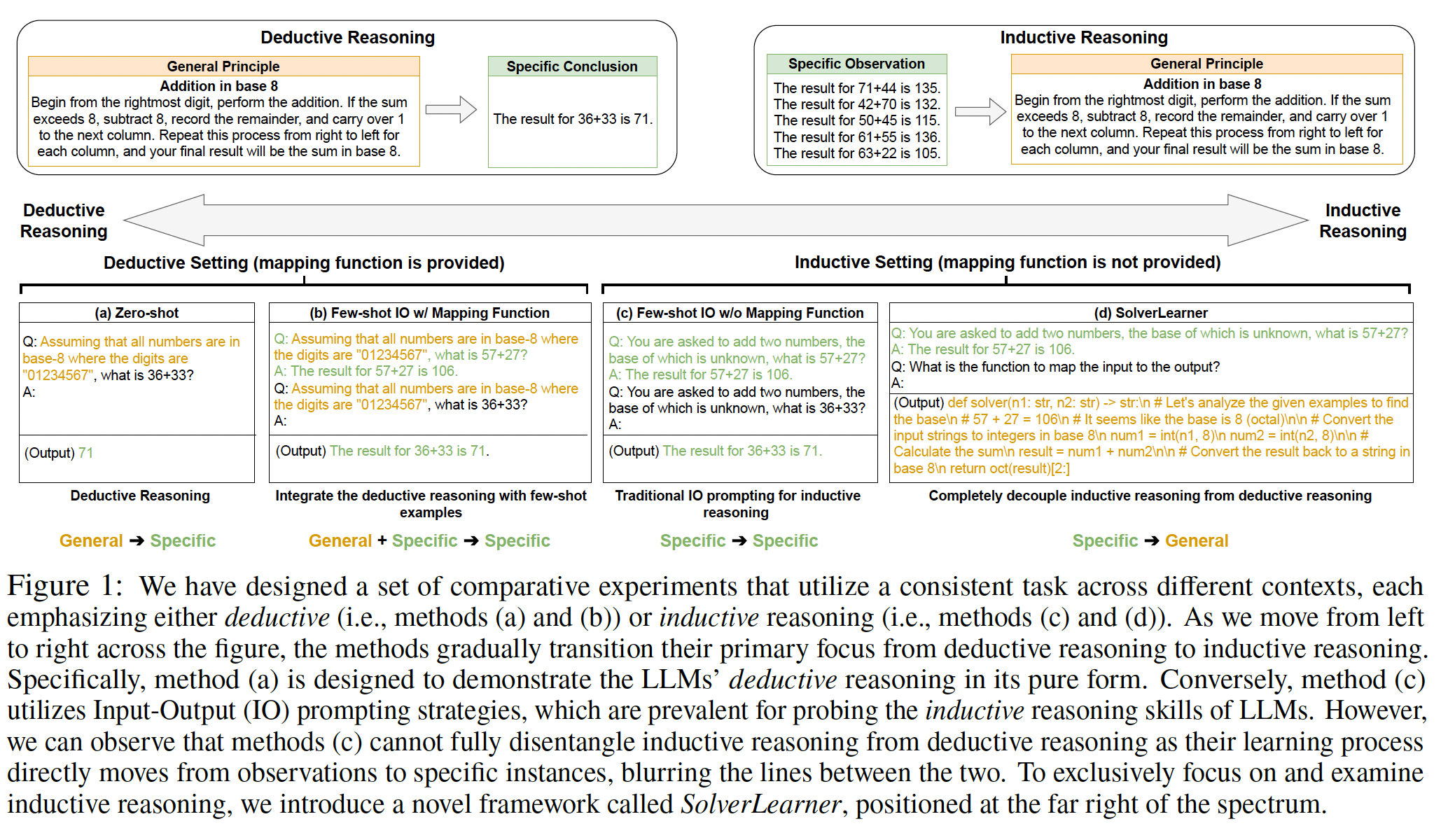 Reasoning encompasses two typical types: deductive reasoning and inductive reasoning. Despite extensive research i…
Language models can be prompted to reason through problems in a manner that significantly improves performance. However, why such prompting improves performance is unclear. Recent work showed that usi…
However, the quality and transparency of their internal reasoning processes remain underexplored. This work moves beyond the final-answer accuracy and investigates step-by-step reasoning in the medica…
What does it truly mean for a language model to “reason” strategically, and can scaling up alone guarantee intelligent, context-aware decisions? Strategic decision-making requires adaptive reasoning, …
The emergent few-shot reasoning capabilities of Large Language Models (LLMs) have excited the natural language and machine learning community over recent years. Despite of numerous successful applicat…
To address this issue, some studies employ the approach of propositional logic to further enhance logical reasoning abilities of LLMs. However, the potential omissions in the extraction of logical exp…
We conduct detailed analysis with a range of LLMs such as GPT-4, ChatGPT, Gemini, Llama-2, and Mistral using chain-of-thought prompting. Experimental results show that existing LLMs do not fare well o…
With the emergence of advanced reasoning models like OpenAI o3 and DeepSeek-R1, large language models (LLMs) have demonstrated remarkable reasoning capabilities. However, their ability to perform rigo…
 Large language models (LLMs) have accomplished remarkable reasoning performance in various domains. However, in th…
Investigating the reasoning abilities of transformer models, and discovering new challenging tasks for them, has been a topic of much interest. Recent studies have found these models to be surprisingl…
Large language models (LLMs) have shown impressive performance on reasoning benchmarks like math and logic. While many works have largely assumed well-defined tasks, real-world queries are often under…
The impressive performance of recent language models across a wide range of tasks suggests that they possess a degree of abstract reasoning skills. Are these skills general and transferable, or specia…
in addition to these associative “System 1” tasks, recent advances in Chain-of-thought prompt learning have demonstrated strong “System 2” reasoning abilities, answering a question in the field of art…
This paper explores the impact of extending input lengths on the capabilities of Large Language Models (LLMs). Despite LLMs advancements in recent times, their performance consistency across different…
Injecting a collection of symbolic data directly into the training of LLMs can be problematic, as it disregards the synergies among different symbolic families and overlooks the need for a balanced mi…
Reasoning based on Large Language Models (LLMs) has garnered increasing attention due to outstanding performance of these models in mathematical and complex logical tasks. Beginning with the Chain-of-…