Inductive reasoning is fundamental to both human and artificial intelligence. The inductive reasoning abilities of current Large Language Models (LLMs) are evaluated in this research. We argue that on…
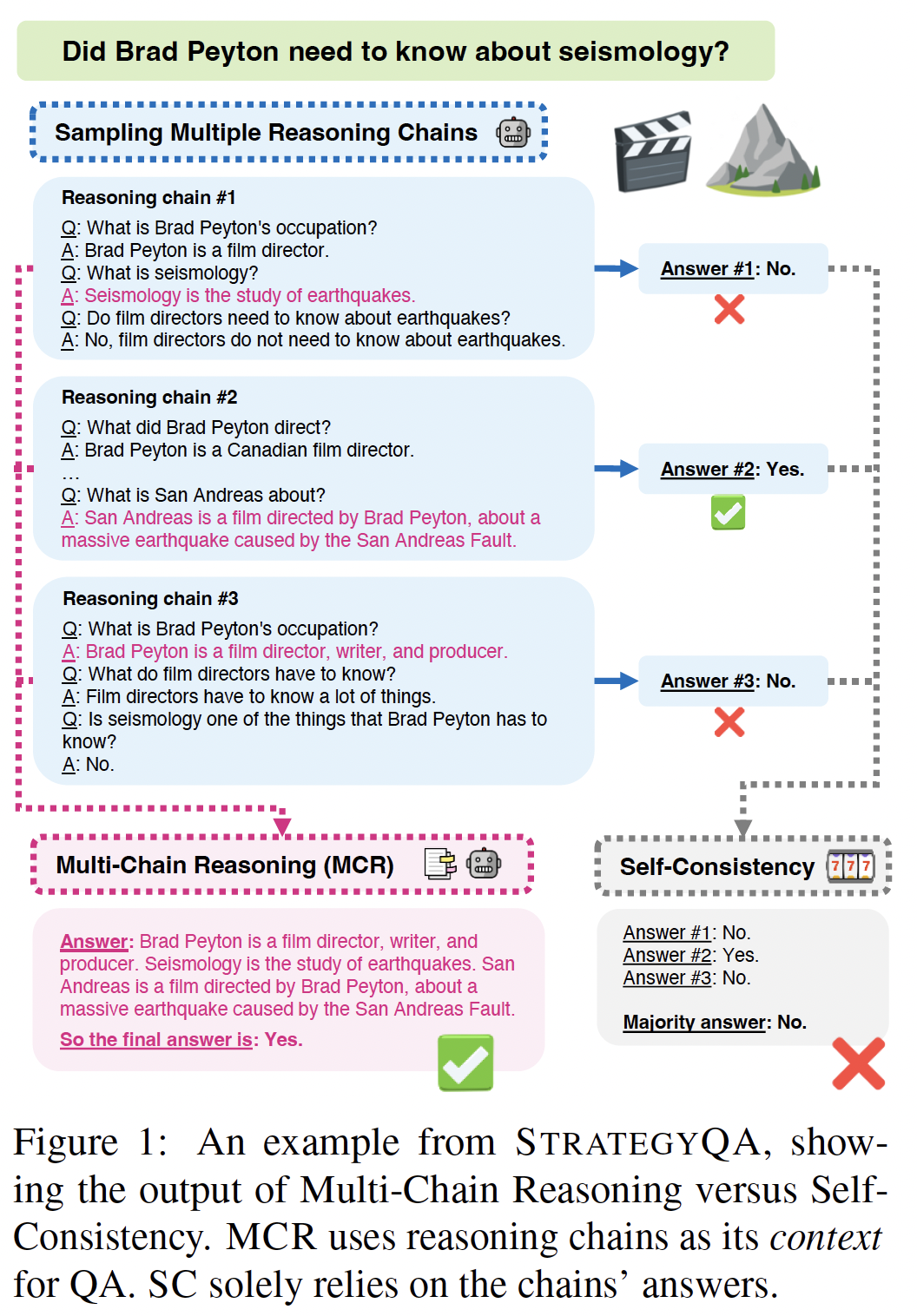 Modern systems for multi-hop question answering (QA) typically break questi…
When language models (LMs) are trained via reinforcement learning (RL) to generate natural language “reasoning chains”, their performance improves on a variety of difficult question answering tasks. T…
If autoresearch is itself a form of research, then autoresearch can be applied to research itself. We take this idea literally: we use an autoresearch loop to optimize the autoresearch loop. Every exi…
When AI systems explain their reasoning step-by-step, practitioners often assume these explanations reveal what actually influenced the AI's answer. We tested this assumption by embedding hints into q…
Supervised Fine-Tuning (SFT) is commonly used to train language models to imitate annotated responses for given instructions. In this paper, we challenge this paradigm and propose Critique Fine-Tuning…
Real-time human-artificial intelligence (AI) collaboration is crucial yet challenging, especially when AI agents must adapt to diverse and unseen human behaviors in dynamic scenarios. Existing large l…
While large language models (LLMs) leverage both knowledge and reasoning during inference, the capacity to distinguish between them plays a pivotal role in model analysis, interpretability, and develo…
We propose DialogueReason, a reasoning paradigm that uncovers the lost roles in monologue-style reasoning models, aiming to boost diversity and coherency of the reasoning process. Recent advances in R…
“We introduce a new benchmark, Diplomat, aiming at a unified paradigm for pragmatic reasoning and situated conversational understanding. Compared with previous works that treat different figurative ex…
Reinforcement learning (RL) training of large language models (LLMs) on unverifiable tasks is challenging even when a reasonable-quality reference answer is available. We propose a constrained RL trai…
we devise a similar strategy that breaks down reasoning tasks into a problem decomposition phase and a problem solving phase and show that the strategy is able to outperform a single stage solution. F…
regularities in language range from phonology to pragmatics. For example, people associate different sounds with different referents (e.g., Köhler, 1929), automatically reinterpret implausible sentenc…
Large Reasoning Models (LRMs) have shown remarkable reasoning capabilities, yet they often suffer from overthinking, expending redundant computational steps on simple problems, or underthinking, faili…
still struggle on complex reasoning tasks, which drives the research on cognitive behaviors of LLMs to explore human-like problem-solving strategies. Along this direction, one representative strategy …
Large language models have recently demonstrated significant gains in reasoning ability, often attributed to their capacity to generate longer chains of thought and engage in reflective reasoning. How…
Structured reasoning over natural language inputs remains a core challenge in artificial intelligence, as it requires bridging the gap between unstructured linguistic expressions and formal logical re…
Adopting human and large language models (LLM) as judges (a.k.a human- and LLM-as-ajudge) for evaluating the performance of LLMs has recently gained attention. Nonetheless, this approach concurrently …
Our key contributions are: 1) We conduct the first investigation of the feasibility of using LLMs in intelligence analysis where both evidencebased reasoning and analytical creativity is of utmost …
Learning from mistakes is a fundamental feature of human intelligence. Previous work has shown that Large Language Models (LLMs) can also learn from incorrect answers when provided with a comprehensiv…
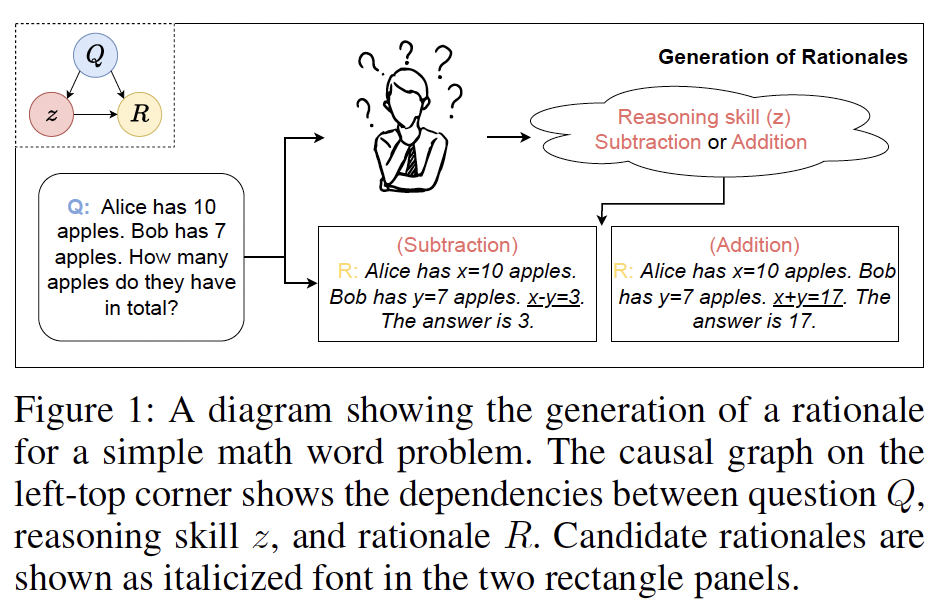 Recent advances in Large Language Models (LLMs) have led to an emergent ability o…
LLM-as-a-Judge models generate chain-of-thought (CoT) sequences intended to capture the step-by-step reasoning process that underlies the final evaluation of a response. However, due to the lack of hu…
Agents based on large language models (LLMs) for machine learning engineering (MLE) can automatically implement ML models via code generation. However, existing approaches to build such agents often r…
Large Reasoning Models (LRMs) have significantly enhanced their capabilities in complex problem-solving by introducing a thinking draft that enables multipath Chain-of-Thought explorations before prod…
To address these issues, we introduce Meta- Reasoner, a framework that dynamically optimizes inference-time reasoning by enabling LLMs to “think about how to think.” Drawing inspiration from human met…
Large language models (LLMs) now solve multi-step problems by emitting extended chains of thought. During the process, they often re-derive the same intermediate steps across problems, inflating token…
Large Language Models (LLMs) have demonstrated significant improvements in reasoning capabilities through supervised fine-tuning and reinforcement learning. However, when training reasoning models, th…
Large language models (LLMs) have achieved remarkable performance in recent years but are fundamentally limited by the underlying training data. To improve models beyond the training data, recent work…
vanilla-retrieved information tends to lack depth, utility, and suffers from redundancy, which negatively impacts the quality of generated articles, leading to shallow, repetitive, and unoriginal outp…
Intermediate token generation (ITG), where a model produces output before the solution, has been proposed as a method to improve the performance of language models on reasoning tasks. While these reas…
In this paper, we demonstrate the limitations of such methods and rethink what it means for AI to be proactive in multi-party, human-AI conversations. We propose that just like humans, rather than mer…
Large language models (LLMs) are effective at answering questions that are clearly asked. However, when faced with ambiguous queries they can act unpredictably and produce incorrect outputs. This unde…
[**https://arxiv.org/abs/2403.09629**](https://arxiv.org/abs/2403.09629) For example, this applies to the steps not stated between the lines of a proof or to the theory of mind underlying a conversat…
Large Language Models (LLMs) show remarkable potential for few-shot information extraction (IE), yet their performance is highly sensitive to the choice of in-context examples. Conventional selection …
it remains challenging for these language agents to quickly and efficiently learn from trial-and-error as traditional reinforcement learning methods require extensive training samples and expensive mo…
we propose Reversal of Thought (RoT), a novel framework aimed at enhancing the logical reasoning abilities of LLMs. RoT utilizes a Preference-Guided Reverse Reasoning warm-up strategy, which integrate…
Modern AI systems are notoriously opaque, limiting efforts to understand or audit their behaviors [42, 188]. In response, Explainable Artificial Intelligence (XAI) aims to foster trust and accountabil…
Large “instruction-tuned” language models (i.e., finetuned to respond to instructions) have demonstrated a remarkable ability to generalize zero-shot to new tasks. Nevertheless, they depend heavily on…
Instruction tuning is critical to large language models (LLMs) for achieving better instruction following and task adaptation capabilities but its success heavily relies on the training data quality. …
*Table 2. All 39 reasoning modules consisting of high-level cognitive heuristics for problem-solving. We adopt them from Fernando et al.* (_2023_). Reasoning Modules 1 How could I devise an experim…
Despite their remarkable capabilities, large language models (LLMs) often produce responses containing factual inaccuracies due to their sole reliance on the parametric knowledge they encapsulate. Ret…
To reveal when a large language model (LLM) is uncertain about a response, uncertainty quantification commonly produces percentage numbers along with the output. But is this all we can do? We argue th…
We investigate how to elicit compositional generalization capabilities in large language models (LLMs). Compositional generalization empowers LLMs to solve complex problems by combining foundational s…
Soft attention in Transformer-based Large Language Models (LLMs) is susceptible to incorporating irrelevant information from the context into its latent representations, which adversely affects next t…
[**https://arxiv.org/abs/2403.04642**](https://arxiv.org/abs/2403.04642) [[Reinforcement Learning]] Reinforcement Learning from Human Feedback (RLHF) has emerged as a dominant approach for aligning …
We introduce our first reflective generative model MetaStone-S1, which obtains OpenAI o3- mini’s performance via the new Reflective Generative Form. The new form focuses on highquality reasoning traje…
Self-detection for Large Language Models (LLMs) seeks to evaluate the trustworthiness of the LLM’s output by leveraging its own capabilities, thereby alleviating the issue of output hallucination. How…
Transformer-based causal language models generate tokens one after the other in immediate succession. To generate the (K + 1)th token, the model consumes the K previous tokens, and proceeds layer by l…
This paper introduces a simple and scalable approach to improve the data efficiency of large language model (LLM) training by augmenting existing text data with thinking trajectories. The compute for …
Despite the impressive capabilities of Large Language Models (LLMs) on various tasks, they still struggle with scenarios that involves complex reasoning and planning. Recent work proposed advanced pro…
Abstract. While large language models demonstrate impressive performance on static benchmarks, the true potential of large language models as self-learning and reasoning agents in dynamic environments…
Abstract. Benchmarks such as SWE-bench and ARC-AGI demonstrate how shared datasets accelerate progress toward artificial general intelligence (AGI). We introduce VCBench, the first benchmark for predi…
we set out to clarify these capabilities under a more stringent evaluation setting in which we disallow any kind of external feedback. Our findings under this setting show a split: while self-reflecti…