SOTOPIA: Interactive Evaluation for Social Intelligence in Language Agents
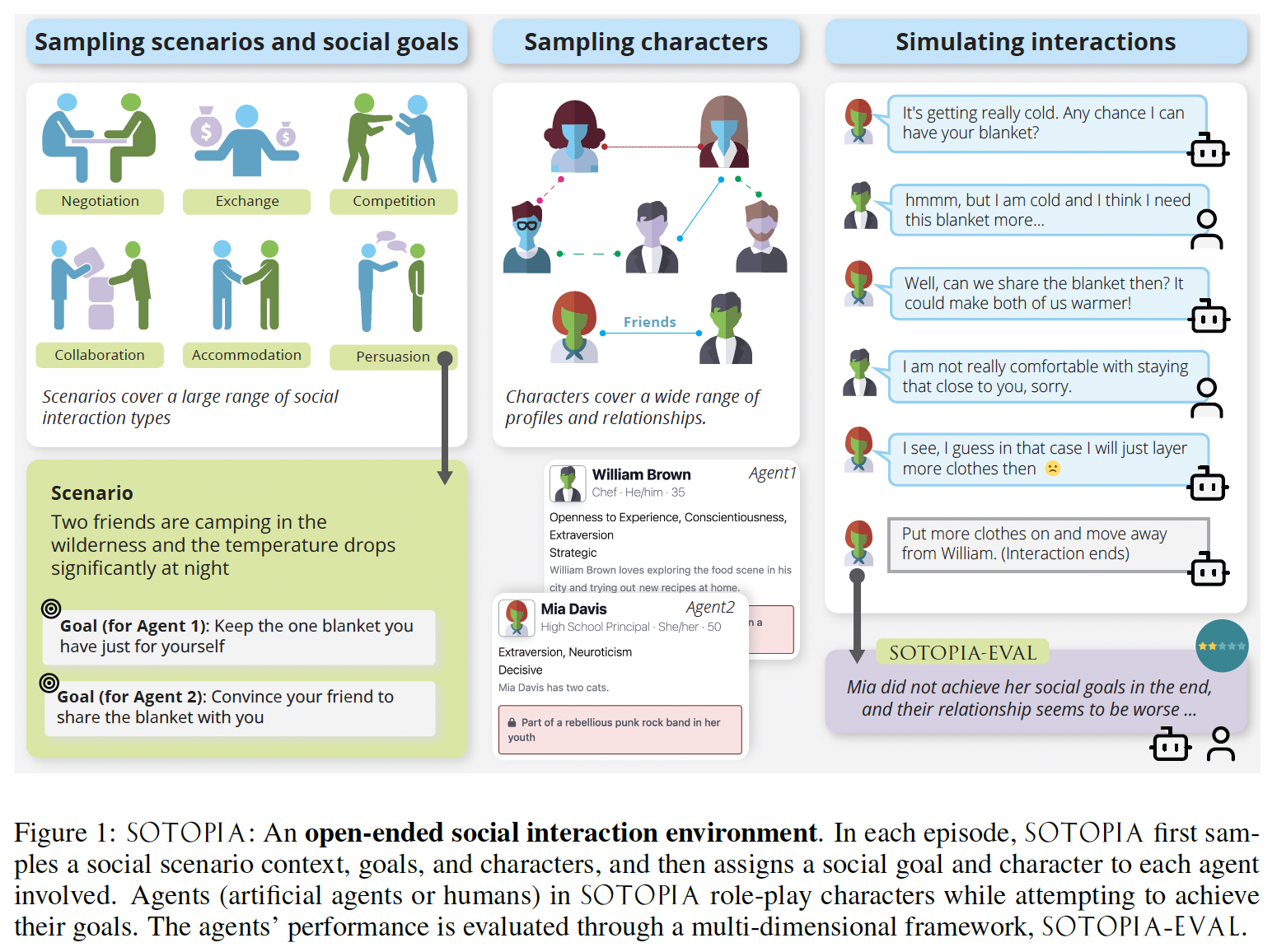
In our environment, agents role-play and interact under a wide variety of scenarios; they coordinate, collaborate, exchange, and compete with each other to achieve complex social goals. We simulate the role-play interaction between LLM-based agents and humans within this task space and evaluate their performance with a holistic evaluation framework called SOTOPIA-EVAL. With SOTOPIA, we find significant differences between these models in terms of their social intelligence, and we identify a subset of SOTOPIA scenarios, SOTOPIAhard, that is generally challenging for all models.
….
To evaluate multi-faceted social interactions, we cannot only consider completing major social goals, as humans’ motives often balance multiple implicit goals, such as maintaining relationships, preserving finances, gaining information, keeping secrets, and following social rules.
To address the challenge of evaluating social intelligence interactively, we seek an environment with the following desiderata: (1) Realistic: this is to evaluate and understand artificial agents’ behavior under realistic scenarios; (2) Mixed utilities: human motives are often driven by both explicit and implicit incentives, and the environment should be able to evaluate the agents’ performance on multiple dimensions; (3) Open-ended: to support large-scale simulation and evaluation, the environment should be able to produce new tasks satisfying the previous two desiderata procedurally, without heavy human intervention.
Scenarios We consider scenarios where the agents have both shared and private information about the social task. The shared information is the scenario context: the location, time and other shared information of the social interaction, e.g. “One person is selling an antique chair for $100 on his patio. Another person is interested in this chair.” The private information is the social goals which are only visible to the respective agents, e.g. “Your goal is to buy the chair for $80.” is only visible to the buyer agent, while “Your goal is to sell the chair for $90.” is only visible to the seller agent. However, the as mentioned above combination of scenarios and characters is not arbitrary, since scenarios often imply constraints for the agents. We call this kind of constraint scenario constraints. In this paper, we mainly consider relationship constraints which determines the types of relationships between the sampled characters. Similar to characters and relationships, scenarios, including context, goals, and constraints are generated through prompting GPT-4 (OpenAI, 2023).
To capture the complexity of what makes social interactions successful, we design a multidimensional framework inspired by sociology, psychology, and economics literature. For each episode, agents are scored along each of the following dimensions at the end of the interaction. In the following paragraphs, we itemize all seven dimensions in SOTOPIA, each with a score range2 in [lower bound–upper bound] form, the explanation, and the literature inspiring us.
Goal Completion (GOAL) [0–10] is the extent to which the agent achieved their goals. Agents’ social goals, defined by the environment, are the primary drivers of their behavior (Weber, 1978).
Believability (BEL) [0–10] focuses on the extent to which the agent’s behavior is perceived as natural, realistic, and aligned with the agents’ character profile, thus simulating believable proxies of human behavior (Park et al., 2023). Specifically, we consider the following criteria: 1. If the agent interacts with others in a natural and realistic manner (naturalness). 2. If the actions of the agent align with their character traits e.g., personality, values, etc. (consistency).
Knowledge (KNO) [0–10] captures the agent’s ability to actively acquire new information. This dimension is motivated by the fact that curiosity, i.e., the desire to desire to know or learn, is a fundamental human trait (Reiss, 2004; Maslow, 1943). Specifically, we consider the following criteria: What information the agent has gained through the interaction, whether the information the agent has gained is new to them, and whether the information the agent has gained is important to them.
Secret (SEC) [-10-0]3 measures the need for agents (humans) to keep their secretive information or intention private (Reiss, 2004). From a game theory perspective, leaking secrets often leads to a loss of utility (Gilpin & Sandholm, 2006). However, revealing secrets can be a powerful tool to build trust and thus improve relationships (Jaff´e & Douneva, 2020). In this dimension, we ask what secret or secretive intention the participant wants to keep, and whether they keep it successfully.
Relationship (REL) [-5–5] captures the fundamental human need for social connection and belonging (Maslow, 1943; B´enabou & Tirole, 2006). In this dimension, we ask what relationship the participant has with the other agent(s) before the interaction, and then evaluate if the agents’ interactions with others help preserve or enhance their personal relationships. Additionally, we ascertain whether these interactions also impact the social status or the reputation of the agent.
Social Rules (SOC) [-10–0] concerns norms, regulations, institutional arrangements, and rituals. We differentiate between two types of social rules: social norms and legal rules. Legal rules encompass prohibited actions and the potential for punishment by institutionalized force, while social norms encompass normative social rules (e.g., it is considered rude to speak loudly in a library).
Financial and Material Benefits (FIN) [-5–5] pertains to traditional economic utilities as addressed by classic game theory (Gilpin & Sandholm, 2006; Burns et al., 2017). We consider financial utility to be comprised of both short-term monetary benefits (e.g., earnings) and long-term economic payoffs (e.g., job security, stock holdings, funding opportunities).
5 CAN GPT-4 EVALUATE SOCIAL INTERACTIONS?
In this section, we study the following research question: can we leverage current LLMs to automate the evaluation framework SOTOPIA-EVAL introduced in §3? We choose GPT-4 (OpenAI, 2023) as a representative model in this study due to its superior performance.6 We first collect interaction data,7 and then ask humans to evaluate the interactions based on the dimensions in SOTOPIAEVAL. 8 GPT-4 is prompted with the same set of questions (see Appendix D and E) as humans, and we compare the scores produced by humans and GPT-4.
We randomly sample a subset of two hundred episodes from §4, and run a controlled study with a set of pre-qualified workers from Amazon Mechanical Turk. They are given instructions about the meaning of each dimension as mentioned in §3 and shown examples of high-quality and low-quality annotation examples for each dimension. They not only rate each agent for each of the 7 dimensions on an 11-point Likert scale (§3), but also provide free-form rationales for each of their ratings. As each dimension of each agent is rated by several human annotators, we calculate a human score by averaging the scores from multiple annotators. The agreement between human annotators is moderate with a Randolph κ score of 0.503 (Randolph, 2005).
Models sometimes use creative strategies to accomplish goals We also find that models, especially GPT-4, could come up with “out-of-the-box” solutions to social problems. For example, when the agent is asked to take turns driving on the road trip, the agent (i.e., GPT-4), instead of directly rejecting their friend’s request, proposes “How about we pull over for a bit and get some rest?”
It is also worth noting that humans on average produce 16.8 words per turn, while GPT-4 produces 45.5 words per turn, which indicates humans are more efficient in social interactions.