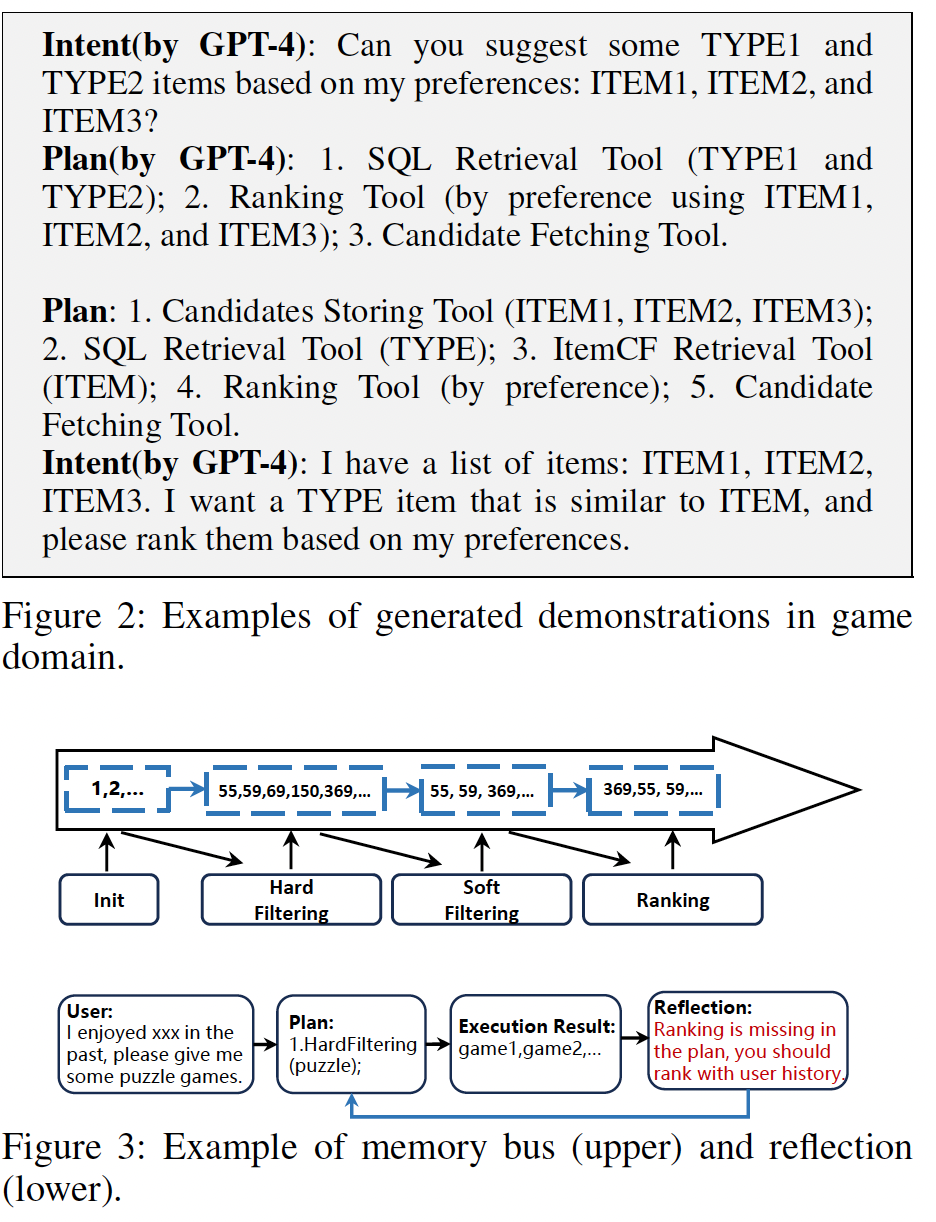
Recommender AI Agent: Integrating Large Language Models for Interactive Recommendations
However, LLMs lack the knowledge of domain-specific item catalogs and behavioral patterns, particularly in areas that diverge from general world knowledge, such as online e-commerce. Finetuning LLMs for each domain is neither economic nor efficient. In this paper, we bridge the gap between recommender models and LLMs, combining their respective strengths to create a versatile and interactive recommender system. We introduce an efficient framework called InteRecAgent, which employs LLMs as the brain and recommender models as tools. We first outline a minimal set of essential tools required to transform LLMs into InteRecAgent. We then propose an efficient workflow within InteRecAgent for task execution, incorporating key components such as memory components, dynamic demonstration-augmented task planning, and reflection. InteRecAgent enables traditional recommender systems, such as those ID-based matrix factorization models, to become interactive systems with a natural language interface through the integration of LLMs. Experimental results on several public datasets show that InteRecAgent achieves satisfying performance as a conversational recommender system, outperforming general-purpose LLMs.
1.1 Conversational Recommender System
Existing researches in conversational recommender systems (CRS) can be primarily categorized into two main areas (Gao et al. 2021): attribute-based question-answering(Zou and Kanoulas 2019; Zou, Chen, and Kanoulas 2020; Xu et al. 2021) and open-ended conversation (Li et al. 2018; Wang et al. 2022b, 2021). In attribute-based question-answering CRS, the system aims to recommend suitable items to users within as few rounds as possible. The interaction between the system and users primarily revolves around question-answering concerning desired item attributes, iteratively refining user interests. Key research challenges in this area include developing strategies for selecting queried attributes (Mirzadeh, Ricci, and Bansal 2005; Zhang et al. 2018) and addressing the exploration-exploitation trade-off (Christakopoulou, Radlinski, and Hofmann 2016; Xie et al. 2021). In open-ended conversation CRS, the system manages free-format conversational data. Initial research efforts in this area focused on leveraging pretrained language models for conversation understanding and response generation (Li et al. 2018; Penha and Hauff 2020). Subsequent studies incorporated external knowledge to enhance the performance of open-ended CRS (Chen et al. 2019; Wang, Su, and Chen 2022; Wang et al. 2022b). Nevertheless, these approaches struggle to reason with complex user inquiries and maintain seamless communication with users. The emergence of LLMs presents an opportunity to revolutionize the construction of conversational recommender systems, potentially addressing the limitations of existing approaches and enhancing the overall user experience.
The core idea is to utilize LLMs as the “brains” and in-domain models as “tools” that extend LLMs’ capabilities when handling domain-specific tasks.
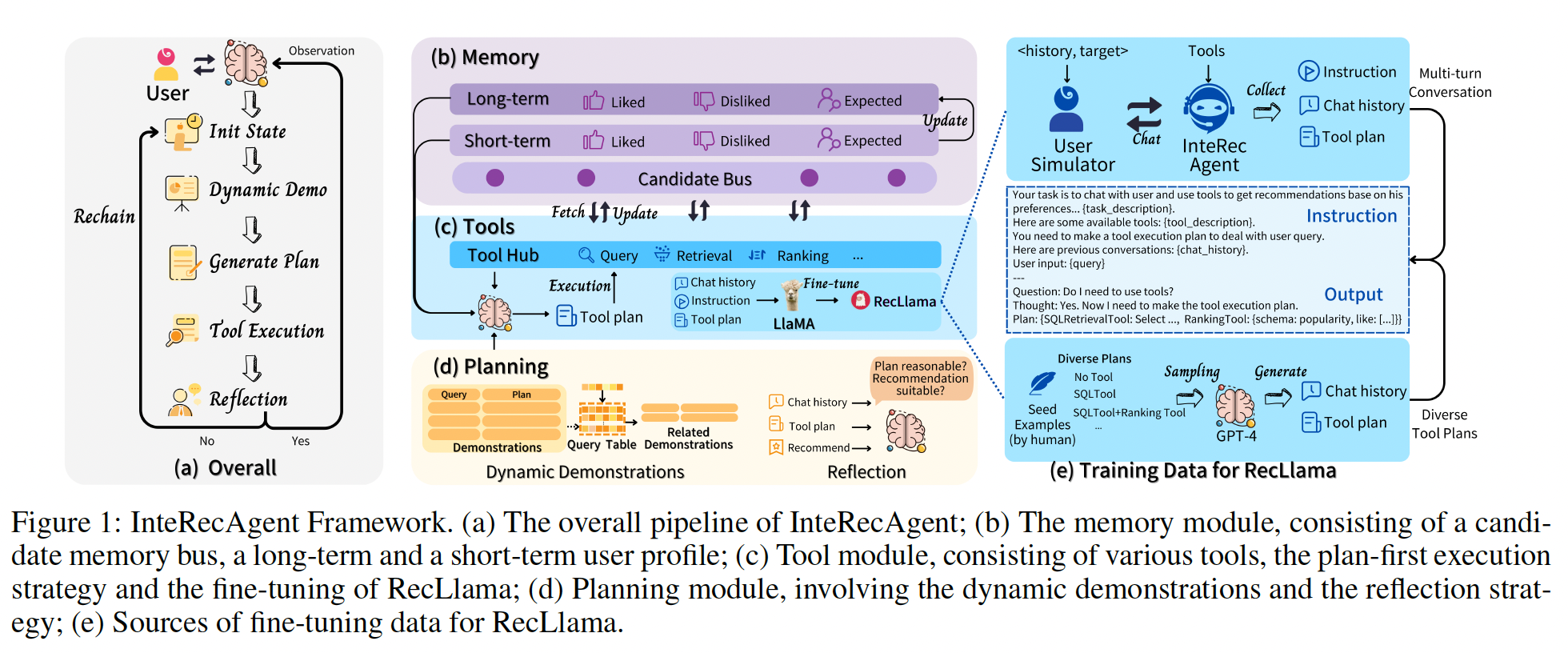
In this paper, we connect LLMs with traditional recommendation models for interactive recommender systems. We propose InteRecAgent (Interactive Recommender Agent), a framework explicitly designed to cater to the specific requirements and nuances of recommender systems, thereby establishing a more effective connection between the LLM’s general capabilities and the specialized needs of the recommendation domain. This framework consists of three distinct sets of tools, including querying, retrieval, and ranking, which are designed to cater to the diverse needs of users’ daily inquiries. Given the typically large number of item candidates, storing item names in the tools’ input and output as observations with prompts is impractical. Therefore, we introduce a “shared candidate bus” to store intermediate states and facilitate communication between tools. To enhance the capabilities of dealing with long conversations and even lifelong conversations, we introduce a “long-term and short-term user profile” module to track the preferences and history of the user, leveraged as the input of the ranking tool to improve personalization. The “shared candidate bus” along with the “long-term and short-term user profile” constitute the advanced memory mechanisms within the InteRecAgent framework.
Regarding task planning, we employ a “plan-first execution” strategy as opposed to a step-by-step approach. This strategy not only lowers the inference costs of LLMs but can also be seamlessly integrated with the dynamic demonstration strategy to enhance the quality of plan generation. Specifically, InteRecAgent generates all the steps of tool calling at once and strictly follows the execution plan to accomplish the task. During the conversation, InteRecAgent parses the user’s intent and retrieves a few demonstrations that are most similar to the current intent. These dynamically retrieved demonstrations help LLMs formulate a correct task execution plan. In addition, we implement a reflection strategy, wherein another LLM acts as a critic to evaluate the quality of the results and identify any errors during the task execution. If the results are unsatisfactory or errors are detected, InteRecAgent reverts to the initial state and repeats the plan-then-tool-execution process.
As models show emergent intelligence, researchers have started exploring the potential to leverage LLMs as autonomous agents (Wang et al. 2023a; Zhao, Jin, and Cheng 2023), augmented with memory modules, planning ability, and tool-using capabilities. For example, (Wang et al. 2023c; Zhong et al. 2023; Liu et al. 2023b) have equipped LLMs with an external memory, empowering LLMs with growth potential. Regarding the planning, CoT (Wei et al. 2022; Kojima et al. 2022) and ReAct (Yao et al. 2022) propose to enhance planning by step-wise reasoning; ToT (Yao et al. 2023) and GoT (Besta et al. 2023) introduce multipath reasoning to ensure consistency and correctness; Self- Refine (Madaan et al. 2023) and Reflexion (Shinn et al. 2023) lead the LLMs to reflect on errors, with the ultimate goal of improving their subsequent problem-solving success rates. To possess domain-specific skills, some works (Qin et al. 2023a) study guiding LLMs to use external tools, such as a web search engine (Nakano et al. 2021; Shuster et al. 2022), mathematical tools (Schick et al. 2023; Thoppilan et al. 2022), code interpreters (Gao et al. 2023a; Chen et al. 2022) and visual models (Wu et al. 2023; Shen et al. 2023). To the best of our knowledge, this paper is the first to explore the LLM + tools paradigm in the field of recommender systems.
3.1 The Overall Framework The comprehensive framework of InteRecAgent is depicted in Figure 1. Fundamentally, LLMs function as the brain, while recommendation models serve as tools that supply domain-specific knowledge. Users engage with an LLM using natural language. The LLM interprets users’ intentions and determines whether the current conversation necessitates the assistance of tools. For instance, in a casual chitchat, the LLM will respond based on its own knowledge; whereas for in-domain recommendations, the LLM initiates a chain of tool calls and subsequently generates a response by observing the execution results of the tools. Consequently, the quality of recommendations relies heavily on the tools, making the composition of tools a critical factor in overall performance. To ensure seamless communication between users and InteRecAgent, covering both casual conversation and item recommendations, we propose a minimum set of tools that encompass the following aspects:
(1) Information Query. During conversations, the InteRecAgent not only handles item recommendation tasks but also frequently addresses users’ inquiries. For example, within a gaming platform, users may ask questions like, “What is the release date of this game and how much does it cost?” To accommodate such queries, we include an item information query module. This module can retrieve detailed item information from the backend database using Structured Query Language (SQL) expressions.
(2) Item Retrieval. Retrieval tools aim to propose a list of item candidates that satisfy a user’s demand from the entire item pool. These tools can be compared to the retrieval stage of a recommender system, which narrows down relevant candidates to a smaller list for large-scale serving. In InteRecAgent, we consider two types of demands that a user may express in their intent: hard conditions and soft conditions. Hard conditions refer to explicit demands on items, such as “I want some popular sports games” or “Recommend me some RPG games under $100”. Soft conditions pertain to demands that cannot be explicitly expressed with discrete attributes and require the use of semantic matching models, like “I want some games similar to Call of Duty and Fortnite”. It is essential to incorporate multiple tools to address both conditions. Consequently, we utilize an SQL tool to handle hard conditions, finding candidates from the item database. For soft conditions, we employ an item-to-item tool that matches similar items based on latent embeddings.
(3) Item Ranking. Ranking tools execute a more sophisticated prediction of user preferences on the chosen candidates by leveraging user profiles. Similar to the rankers in conventional recommender systems, these tools typically employ a one-tower architecture. The selection of candidates could emerge from the output of item retrieval tools or be directly supplied by users, as in queries like “Which one is more suitable for me, item A or item B?”. Ranking tools guarantee that the recommended items are not only pertinent to the user’s immediate intent but also consonant with their broader preferences.
LLMs have the potential to handle various user inquiries when supplemented with these diverse tools. For instance, a user may ask, “I’ve played Fortnite and Call of Duty before. Now, I want to play some puzzle games with a release date after Fortnite’s. Do you have any recommendations?” In this scenario, the tool execution sequence would be “SQL Query Tool → SQL Retrieval Tool → Ranker Tool.” First, the release date of Fortnite is queried, then the release date and puzzle genre are interpreted as hard conditions for the SQL retrieval. Finally, Fortnite and Call of Duty are considered as the user profile for the ranking model.
Typically, the tool augmentation is implemented via ReAct (Yao et al. 2022), where LLMs generate reasoning traces, actions, and observations in an interleaved manner. We refer to this style of execution as step-by-step. Our initial implementation also employed the step-by-step approach. However, we soon observed some limitations due to various challenges. Firstly, retrieval tools may return a large number of items, resulting in an excessively long observation prompt for LLMs. Additionally, including numerous entity names in the prompt can degrade LLMs performance. Secondly, despite their powerful intelligence, LLMs may use tools incorrectly to complete tasks, such as selecting the wrong tool to call or omitting key execution steps. To tackle these challenges, we enhance the three critical components of a typical LLM-based agent, namely memory (Section 3.2), task planning (Section 3.3 and 3.4), and tool learning abilities (Section 3.5).
Candidate Bus The large number of items can pose a challenge when attempting to include items generated by tools in prompts as observations for the LLM, due to input context length limitations. Meanwhile, the input of a subsequent tool often depends on the output of preceding tools, necessitating effective communication between tools. Thus, we propose Candidate Bus, which is a separate memory to store the current item candidates, eliminating the need to append them to prompt inputs. The Candidate Bus, accessible by all tools, comprises two parts: a data bus for storing candidate items, and a tracker for recording each tool’s output. The candidate items in the data bus are initialized to include all items at the beginning of each conversation turn by default. At the start of each tool execution, candidate items are read from the data bus, and the data bus is then refreshed with the filtered items at the end of each tool execution. This mechanism allows candidate items to flow sequentially through the various tools in a streaming manner. Notably, users may explicitly specify a set of candidate items in the conversation, such as “Which of these movies do you think is most suitable for me: [Movie List]? ” In this case, the LLM will call a special tool—the memory initialization tool—to set the user-specified items as the initial candidate items. The tracker within the memory serves to record tool execution. Each tool call record is represented as a triplet (fk, ik, ok), where fk denotes the name of the k-th tool, and ik, ok are the input and output of the tool’s execution, such as the number of remaining candidates, runtime errors. The tracker’s main function is to aid the critic in making judgments within the reflection mechanism, acting as the ot in reflect(·), as described in Section 3.4. With the help of the Candidate Bus component, items can be transmitted in a streaming manner between various tools and continuously filtered according to conditions, presenting a funnel-like structure for the recommendation. The tracker’s records can be considered as short-term memory for further reflection.
User Profile To facilitate the invocation of tools, we explicitly maintain a user profile in memory. This profile is structured as a dictionary that encapsulates three facets of user preference: “like”, “dislike”, and “expect”. The “like” and “dislike” facets reflect the user’s favorable and unfavorable tastes, respectively, whereas “expect” monitors the user’s immediate requests during the current dialogue, such as conducting a search, which is not necessarily indicative of the user’s inherent preferences. Each facet may contain content that includes item names or categories. User profiles are synthesized by LLMs based on conversation history. To address situations where the conversation history grows excessively long, such as in lifelong learning scenarios where conversations from all days may be stored for ongoing interactions, we devise two distinct user profiles: one representing long-term memory and another for short-term memory. Should the current dialogue exceed the LLM’s input window size, we partition the dialogue, retrieve the user profile from the preceding segment, and merge it with the existing long-term memory to update the memory state. The short-term memory is consistently derived from the most recent conversations within the current prompt. When it comes to tool invocation, a comprehensive user profile is formed by the combination of both long-term and short-term memories.
Rather than using the step-by-step approach, we adopt a two-phase method. In the first phase, we prompt the LLM to generate a complete tool execution plan based on the user’s intention derived from the dialogue. In the second phase, the LLM strictly adheres to the plan, calling tools in sequence while allowing them to communicate via the Candidate Bus.