POMDP-based Statistical Spoken Dialogue Systems: a Review
Abstract—Statistical dialogue systems are motivated by the need for a data-driven framework that reduces the cost of laboriously hand-crafting complex dialogue managers and that provides robustness against the errors created by speech recognisers operating in noisy environments. By including an explicit Bayesian model of uncertainty and by optimising the policy via a reward-driven process, partially observable Markov decision processes (POMDPs) provide such a framework. However, exact model representation and optimisation is computationally intractable. Hence, the practical application of POMDP-based systems requires efficient algorithms and carefully constructed approximations. This review article provides an overview of the current state of the art in the development of POMDP-based spoken dialogue systems.
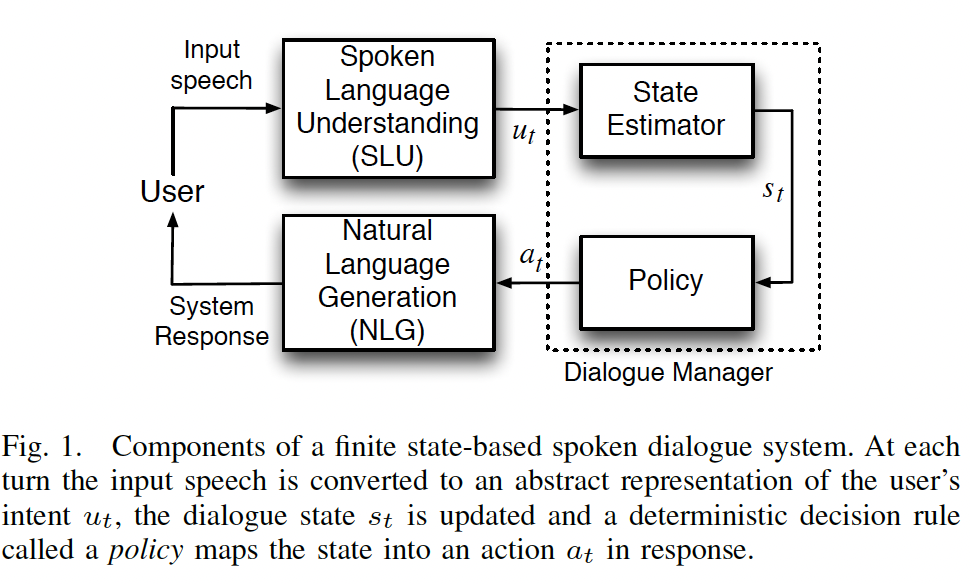
Introduction. I. INTRODUCTION S POKEN dialogue systems (SDS) allow users to interact with a wide variety of information systems using speech as the primary, and often the only, communication medium [1], [2], [3]. Traditionally, SDS have been mostly deployed in call centre applications where the system can reduce the need for a human operator and thereby reduce costs. More recently, the use of speech interfaces in mobile phones has become common with developments such as Apple’s “Siri” and Nuance’s “Dragon Go!” demonstrating the value of integrating natural, conversational speech interactions into mobile products, applications, and services. The principal elements of a conventional SDS are shown in Fig 11. At each turn t, a spoken language understanding (SLU) component converts each spoken input into an abstract semantic representation called a user dialogue act ut. The system updates its internal state st and determines the next system act via a decision rule at = π(st), also known as a policy. The system act at is then converted back into speech via a natural language generation (NLG) component.
Discussion / Conclusion. The development of statistical dialogue systems has been motivated by the need for a data-driven framework that reduces the cost of laboriously hand-crafting complex dialogue managers and which provides robustness against the errors created by speech recognisers operating in noisy environments. By providing an explicit Bayesian model of uncertainty and by providing a reward-driven process for policy optimisation, POMDPs provide such a framework. However, as will be clear from this review, POMDP-based dialogue systems are complex and involve approximations and trade-offs. Good progress has been made but there is still much to do. There are many challenges, most of which have been touched upon in this review such as finding ways to increase the complexity of the dialogue model whilst maintaining tractable belief tracking; and reducing policy learning times so that systems can be trained directly on real users rather than using simulators. Down the road, there is also the task of packaging this technology to make it widely accessible to non-experts in the industrial community.