Exploring the Impact of Large Language Models on Recommender Systems: An Extensive Review
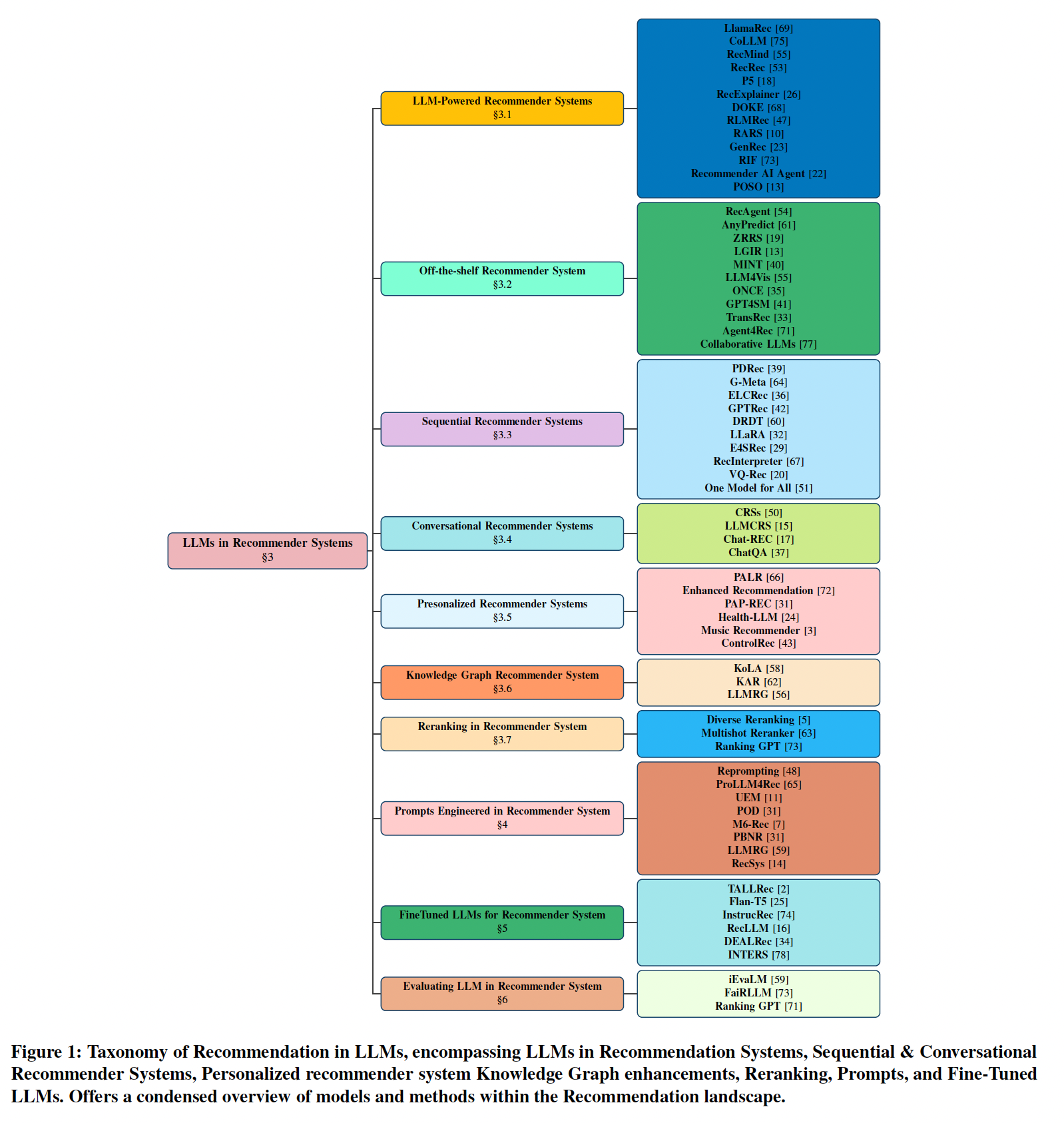
The paper underscores the significance of Large Language Models (LLMs) in reshaping recommender systems, attributing their value to unique reasoning abilities absent in traditional recommenders. Unlike conventional systems lacking direct user interaction data, LLMs exhibit exceptional proficiency in recommending items, showcasing their adeptness in comprehending intricacies of language. This marks a fundamental paradigm shift in the realm of recommendations. Amidst the dynamic research landscape, researchers actively harness the language comprehension and generation capabilities of LLMs to redefine the foundations of recommendation tasks. The investigation thoroughly explores the inherent strengths of LLMs within recommendation frameworks, encompassing nuanced contextual comprehension, seamless transitions across diverse domains, adoption of unified approaches, holistic learning strategies leveraging shared data reservoirs, transparent decision-making, and iterative improvements. Despite their transformative potential, challenges persist, including sensitivity to input prompts, occasional misinterpretations, and unforeseen recommendations, necessitating continuous refinement and evolution in LLM-driven recommender systems.
Introduction. Recommendation systems are crucial for personalized content discovery, and the integration of LLMs in Natural Language Processing (NLP) is revolutionizing these systems [21]. LLMs, with their language comprehension capabilities, recommend items based on contextual understanding, eliminating the need for explicit behavioral data. The current research landscape is witnessing a surge in efforts to leverage LLMs for refining recommender systems, transforming recommendation tasks into exercises in language understanding and generation. These models excel in contextual understanding, adapting to zero and few-shot domains [7], streamlining processes, and reducing environmental impact. This paper delves into how LLMs enhance transparency and interactivity in recommender systems, continuously refining performance through user feedback. Despite challenges, researchers propose approaches to effectively leverage LLMs, aiming to bridge the gap between strengths and challenges for improved system performance.
Discussion / Conclusion. In summary, this paper explores the transformative impact of LLMs in recommender systems, highlighting their versatility and cohesive approach compared to traditional methods. LLMs enhance transparency and interactivity, reshaping user experiences dynamically. The study delves into fine-tuning LLMs for optimized personalized content suggestions and addresses evaluating LLM models in recommendations, providing guidance for researchers and practitioners. Lastly, it touches upon the intricate ranking process in LLMdriven recommendation systems, offering valuable insights for designers and developers aiming to leverage LLMs effectively. This comprehensive exploration not only underscores their current impact but also lays the groundwork for future advancements in recommender systems.