Discursive Socratic Questioning: Evaluating the Faithfulness of Language Models’ Understanding of Discourse Relations
While large language models have significantly enhanced the effectiveness of discourse relation classifications, it remains unclear whether their comprehension is faithful and reliable. We provide DISQ, a new method for evaluating the faithfulness of understanding discourse based on question answering. We first employ in-context learning to annotate the reasoning for discourse comprehension, based on the connections among key events within the discourse. Following this, DISQ interrogates the model with a sequence of questions to assess its grasp of core event relations, its resilience to counterfactual queries, as well as its consistency to its previous responses.
What to Ask: While many discourse spans can form questions, not all provide salient insights into discourse understanding. While previous research like e-SNLI (Camburu et al., 2018) rely on labor-intensive human annotations to extract relevant signals for natural language inference, we advocate the use of in-context learning (ICL). This harnesses the power of large language models to annotate salient discourse signals efficiently. How to Ask: The manner in which questions are framed is essential for assessing three key attributes of a model’s faithfulness: (1) Responsiveness to Targets: We generate questions centered on key spans with ground-truth semantics, to which the model should respond affirmatively (e.g., affirming a cause in a contingency relation). (2) Robustness to Counterfactuals: We design questions based on counterfactual semantics, expecting the model to negate the query (e.g., dismissing contrast in a contingency relation). (3) Logical Consistency: We formulate converse questions with equivalent semantics, anticipating the model to deliver consistent responses (e.g., aligning answers to a result question with its corresponding reason). Berglund et al. (2024) find that LLMs struggle with the “reversal curse” (finding it hard to infer “B is A” from “A is B”). We introduce this facet as a discourse-centric test to the broader LLM research on models’ logical consistency.
We find that while larger, closed-source models excel in responsiveness, they also struggle with the “reversal curse”, indicating a probabilistic approach to discourse semantics without full logical consistency.
What counts as discourse understanding? Organized text makes sense as discourse elements link the text together. Such linking elements are referred to as cohesive devices (Halliday, 1976), including reference, ellipsis, and lexical cohesion. Formally, two textual spans s1 and s2 are linked by the relation r. We define (s1, s2, r) as an evidence triple to understand the discourse. Concretely, Definition 1. (s1, s2, r) is an evidence triple to understand the discourse, where Arg1 and Arg2 are two given discourse arguments participating in a discourse relation R, and two contiguous spans s1 ∈ Arg1 and s2 ∈ Arg2 link the two arguments into a coherent discourse with semantic relation r.
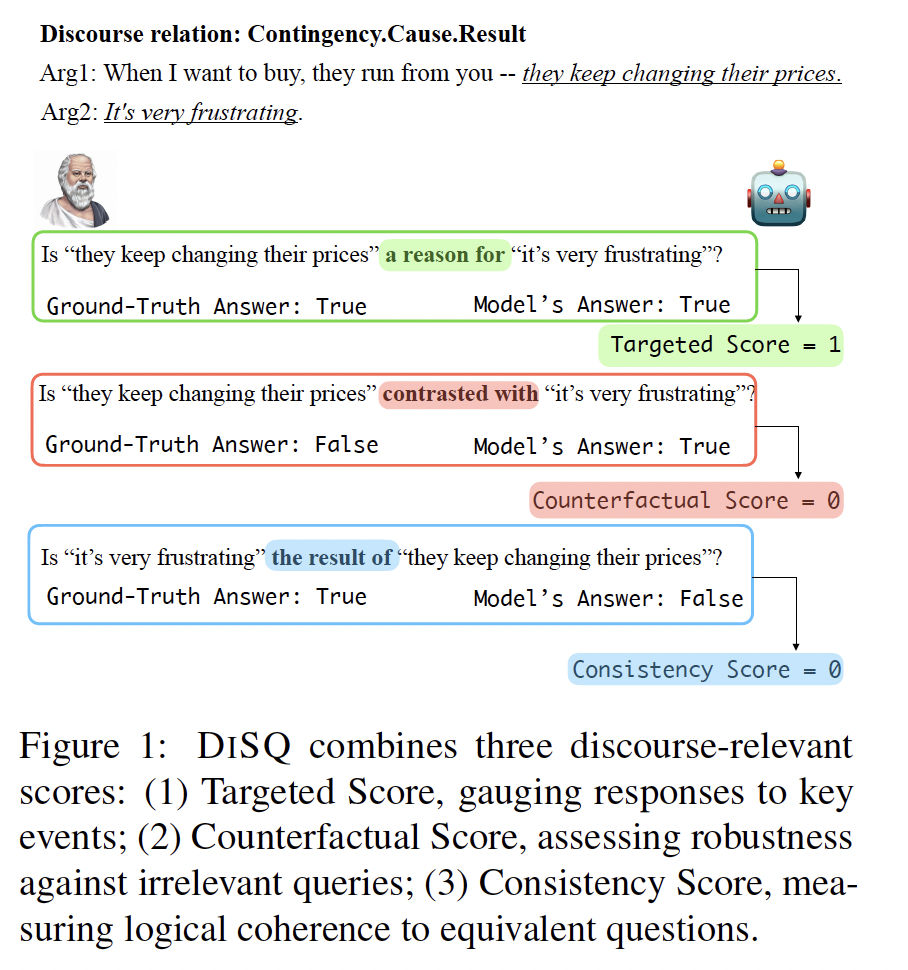
In this paper, we contribute Discursive Socratic Questioning (DISQ), the first systematic evaluation for faithful discourse comprehension. To ensure the reliability of DISQ’s assessment, we employ both intrinsic verification via human annotation and extrinsic evaluation to demonstrate its resilience against domain shifts and paraphrase variations. Our extensive experiments reveal that even leading models like GPT-4 have their shortcomings in DISQ, and that open-source models—despite trailing GPT-4 — can close this gap with fine-tuning on chat and code/math data. To advance LLMs’ understanding, we suggest incorporating linguistic features such as discourse connectives, contextual information, and historical QA data. In the future, we aim to extend our analysis to longer-range discourse, incorporate additional discourse annotation frameworks beyond PDTB, and distilling knowledge from larger models to benefit smaller models.

