Detecting hallucinations in large language models using semantic entropy
Here we develop new methods grounded in statistics, proposing entropy-based uncertainty estimators for LLMs to detect a subset of hallucinations—confabulations—which are arbitrary and incorrect generations. Our method addresses the fact that one idea can be expressed in many ways by computing uncertainty at the level of meaning rather than specific sequences of words. Our method works across datasets and tasks without a priori knowledge of the task, requires no task-specific data and robustly generalizes to new tasks not seen before. By detecting when a prompt is likely to produce a confabulation, our method helps users understand when they must take extra care with LLMs and opens up new possibilities for using LLMs that are otherwise prevented by their unreliability.
Nevertheless, we significantly improve question-answering accuracy for state-of-the-art LLMs, revealing that confabulations are a great source of error at present.
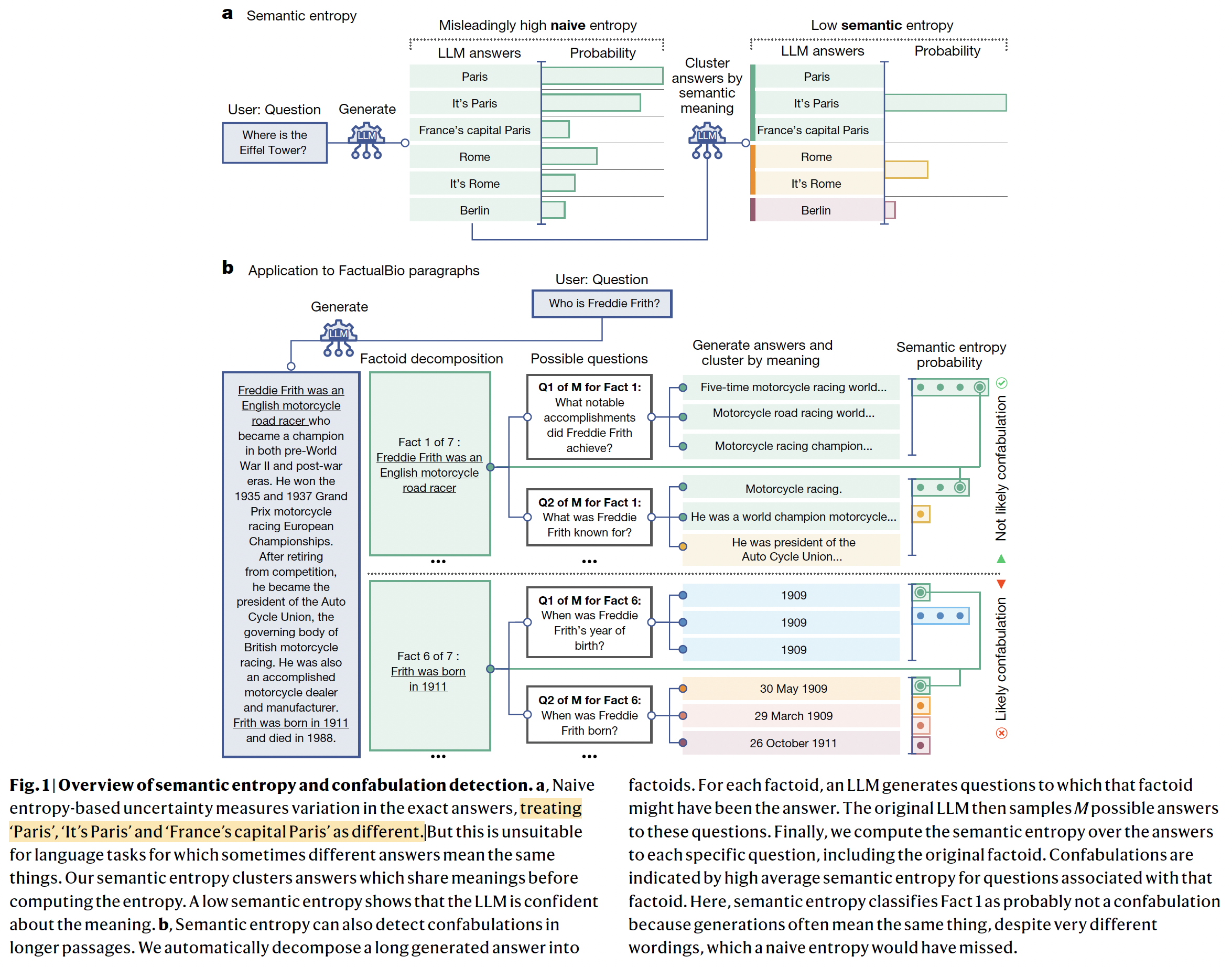
The term hallucination in the context of machine learning originally comes from filling in ungrounded details, either as a deliberate strategy20 or as a reliability problem4. The appropriateness of the metaphor has been questioned as promoting undue anthropomorphism21. Although we agree that metaphor must be used carefully with LLMs22, the widespread adoption of the term hallucination reflects the fact that it points to an important phenomenon. This work represents a step towards making that phenomenon more precise. To detect confabulations, we use probabilistic tools to define and then measure the ‘semantic’ entropy of the generations of an LLM—an entropy that is computed over meanings of sentences. High entropy corresponds to high uncertainty23–25—so semantic entropy is one way to estimate semantic uncertainties. Semantic uncertainty, the broader category of measures we introduce, could be operationalized with other measures of uncertainty, such as mutual information, instead. Entropy in free-form generation is normally hard to measure because answers might mean the same thing (be semantically equivalent) despite being expressed differently (being syntactically or lexically distinct). This causes naive estimates of entropy or other lexical variation scores26 to be misleadingly high when the same correct answer might be written in many ways without changing its meaning.
By contrast, our semantic entropy moves towards estimating the entropy of the distribution of meanings of free-form answers to questions, insofar as that is possible, rather than the distribution over the ‘tokens’ (words or word-pieces) which LLMs natively represent. This can be seen as a kind of semantic consistency check27 for random seed variation. An overview of our approach is provided in Fig. 1 and a worked example in Supplementary Table 1.
Intuitively, our method works by sampling several possible answers to each question and clustering them algorithmically into answers that have similar meanings, which we determine on the basis of whether answers in the same cluster entail each other bidirectionally28. That is, if sentence A entails that sentence B is true and vice versa, then we consider them to be in the same semantic cluster.