Chamain: Harmonizing Character Persona Integrity with Domain-Adaptive Knowledge in Dialogue Generation
Recent advances in large language models (LLMs) have shown their capacity for generating natural dialogues, leveraging extensive pre-trained knowledge. However, the seamless integration of domain-specific knowledge into dialogue agents, without undermining their personas or unique textual style, remains a challenging task. Traditional approaches, such as constructing knowledge-aware character dialogue datasets or training LLMs from the ground up, require considerable resources. Sequentially fine-tuning character chatbots across multiple datasets or applying existing merging techniques often leads to catastrophic forgetting, resulting in the loss of both knowledge and the character’s distinct persona. This compromises the model’s ability to consistently generate character-driven dialogues within a usercentric framework. In this context, we introduce a novel model merging method, Chamain, which effortlessly enhances the performance of character models, much like finding a “free lunch”. Chamain merges domain-specific knowledge into a character model by parameterwise weight combination of instruction-tuned models and learns to reflect persona’s unique characteristics and style through Layer-wise merging.
Researches on open-domain chatbot focus on integrating personas to develop unique AI agents (Zheng et al., 2020). The efforts to make chatbots more human-like are not just for the purpose of obtaining knowledge and information, but to enhance the close interaction between humans and machines (Yin et al., 2023). Such efforts have achieved significant commercial applications, allowing users to craft custom AI agents with character-related information, enhancing user-AI interaction. However, it has been observed that relying solely on prompt design, without additional training, as seen in products like ChatGPT and Character.AI (Character. AI., 2022), presents challenges in displaying a consistent persona throughout dialogues (Wang et al., 2024). Furthermore, despite efforts to preserve style using character-related dialogue data, the necessity of assimilating new knowledge can lead to catastrophic forgetting (He et al., 2021), where the newly acquired information overshadows previously learned character traits (Liu and Mazumder, 2021).
The emergence of model merging as a prominent area of interest is largely due to the challenges associated with supervised fine-tuning (SFT) and multi-task learning. For instance, while SFT is an effective method for optimizing language models for specific tasks (Dodge et al., 2020), it requires the storage and deployment of a separate model for each task. Using SFT would necessitate storing and managing distinct models per each task, increasing complexity and storage demands. Additionally, models often fail to generalize beyond the data or domains they were trained on, presenting challenges in out-of-domain generalization. In contrast, multi-task learning, which strives to train a single model for multiple tasks, brings its own set of challenges. It offers a solution to the inefficiencies of SFT by integrating training across different tasks into a single model. However, this approach necessitates retraining with large and diverse datasets to achieve a balanced representation of each task within the model (Fifty et al., 2021). Such a balance is critical to ensure that all tasks are learned effectively. The need of providing balanced, extensive, and varied data adds complexity and potential costs of multi-task learning, making it a sophisticated and sometimes expensive endeavor. Model merging emerges as a response to these issues, offering a way to integrate the strengths of individual models trained on specific tasks or through multitask learning, while mitigating the limitations of each approach.
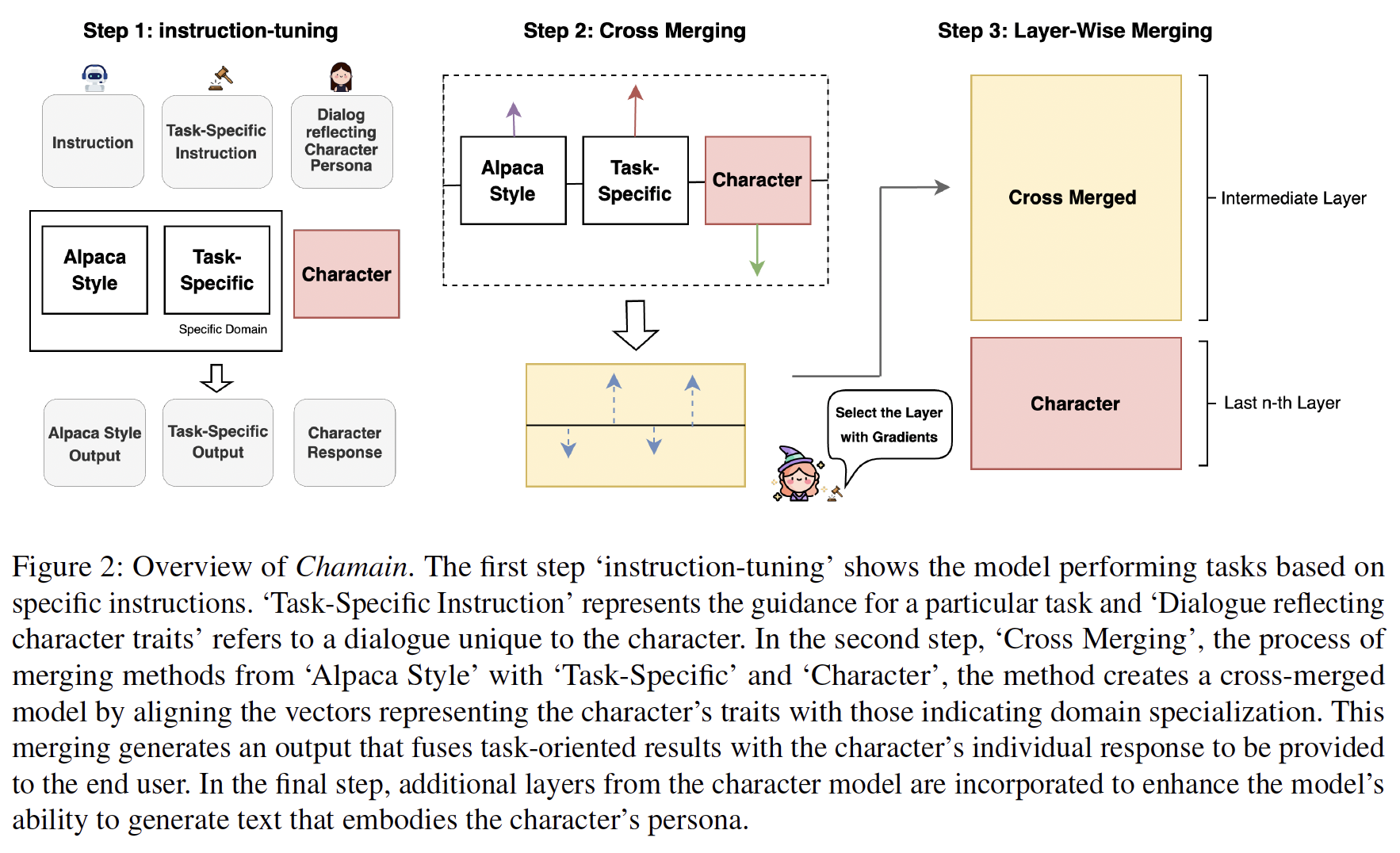
Chamain consists of three main stages: (1) preparing instruction-tuned models for merging, (2) combining task vectors and character vectors of instruction-tuned models, and (3) subsequently fusing the latter layers of the character model based on the layer selection method. It enhances the model’s ability to generate utterances that embody the nuances of the character’s persona. We merge three types of models, a conversation model trained on a self-created persona dataset, an instruction-tuned model on a domain-specific data, and a fine-tuned model for downstream tasks within the domain.
we retained about 80% of the performance of extensively task-specific finetuned models and maintained the ability of character models to portray personalities.
The weight merging technique has emerged as a significant application of NLP in recent years, aiming to combine multiple task-specific models into a unified model. This methodology has been widely adopted in various benchmarks (Kim et al., 2023) due to its ability to enhance performance not only on the target task but also on out-of-domain tasks. Unlike model ensemble methods, which utilizes the predictions of multiple models to generate a final output, weight merging yields a single model through techniques such as interpolating the weights of multiple models or employing task arithmetic (Ilharco et al., 2023). There are various methods for merging the weights of models fine-tuned on different datasets, with traditional approaches including weight averaging. For instance, TIESMerging (Yadav et al., 2023) selectively incorporates changes from fine-tuned models by discarding low-magnitude alterations and merging only those values that align with designated sign, while Dare-TIES (Yu et al., 2023) reduces redundancy by converting the majority of delta parameters to zero. We leverage these merging techniques to develop a chatbot that, by accounting for the distinct traits of chit-chat and knowledge-grounded dialogues, seamlessly integrates knowledge, maintains its persona, and effectively engages in multi-turn conversations to ensure enjoyable interactions.